En 2026, la web no es solo un canal de marketing. Es una superficie operativa. Los cambios en los precios de los competidores, las actualizaciones de las políticas de los proveedores, las ediciones de las páginas de productos, los cambios en las respuestas de las API, las fuentes rotas y los cambios en el lenguaje de cumplimiento pueden afectar los ingresos, el riesgo y la experiencia del cliente en cuestión de minutos.
Es por eso que detectar los cambios rápidamente ya no es un lujo. Es un requisito para los equipos que dependen de páginas web externas, listados de mercado, portales de socios, políticas públicas, fuentes estructuradas y API. Pero la velocidad a menudo se malentende. Un sistema web moderno no simplemente actualiza las páginas con más frecuencia. Combina la cobertura de monitoreo, el filtrado, la ruta de alertas, la confiabilidad y la auditoría en un flujo de trabajo.
Si su equipo quiere menos sorpresas y decisiones más rápidas, aquí está lo que un sistema web moderno necesita para detectar cambios significativos rápidamente sin inundar a todos con ruido.
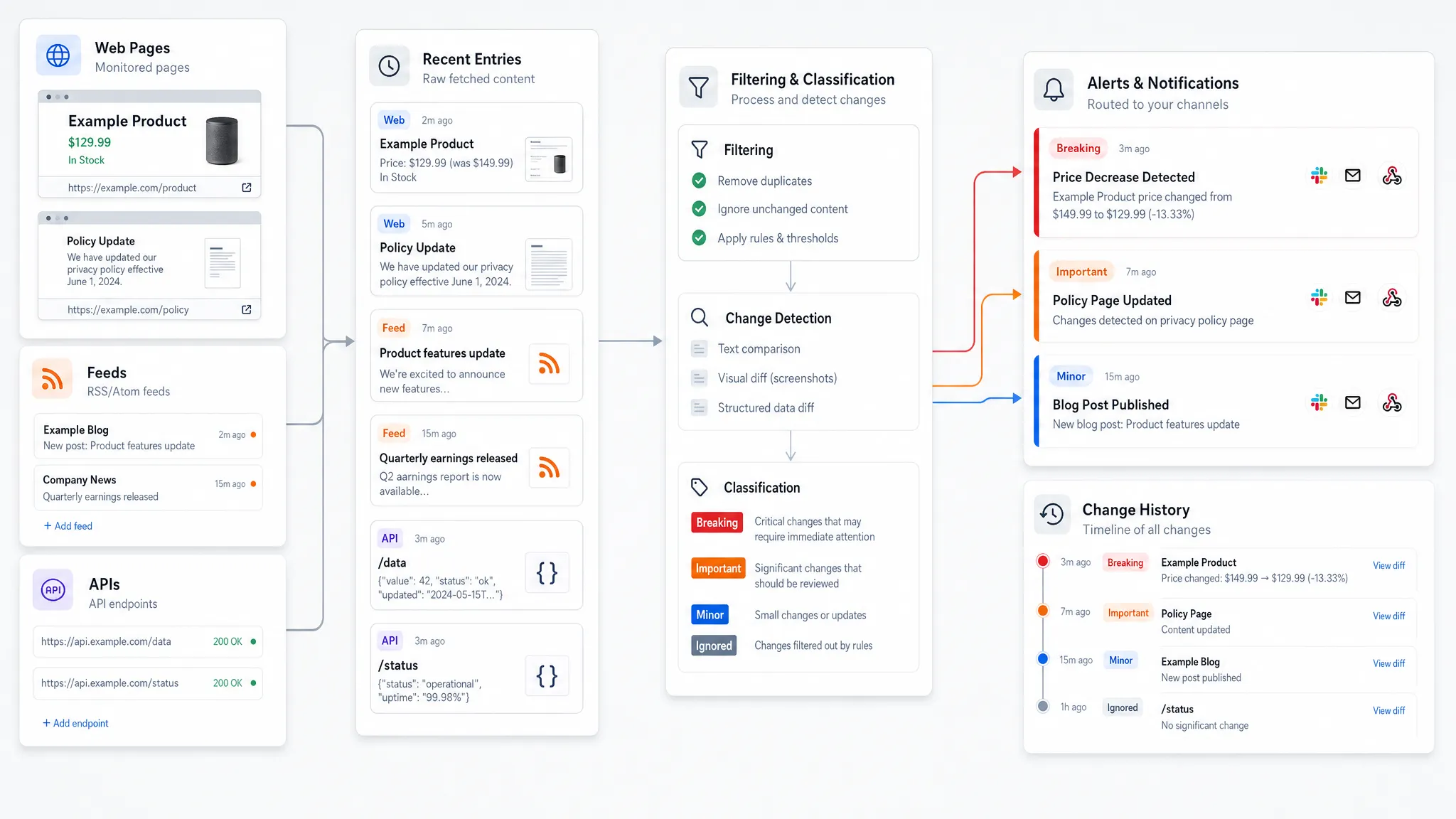
La detección rápida de cambios es un problema de sistema, no de crawler
Un crawler básico puede recuperar una página. Un sistema web moderno tiene que hacer mucho más. Necesita saber qué fuentes son importantes, cuánto tiempo debe verificarlas, qué partes de la fuente son importantes, qué cambió, si el cambio es significativo, quién debe saber y cómo debe registrarse la alerta.
Ese ciclo de vida es importante porque el valor del monitoreo no es la detección en sí. El valor es la acción que sigue. Si un competidor cambia una oferta principal a las 9:00 a.m. y su equipo de ingresos la ve a las 4:00 p.m., técnicamente detectó el cambio, pero no lo detectó lo suficientemente rápido como para responder bien.
Los mejores sistemas tratan el monitoreo de cambios web como una canalización:
El monitoreo de fuentes viene primero, seguido de la comparación, el filtrado de ruido, la entrega de alertas, la integración de flujo de trabajo y el registro histórico. Si algún paso es débil, todo el proceso se ralentiza.
Qué significa realmente rápido
Rápido no significa que cada página debe verificarse cada segundo. Eso sería costoso, ruidoso y innecesario para muchas fuentes. Rápido significa que el sistema puede igualar la urgencia de monitoreo al impacto comercial y entregar la alerta correcta rápidamente cuando ocurre un cambio significativo.
| Capa de velocidad | Qué mide | Por qué es importante |
|---|
| Latencia de detección | Tiempo entre el cambio web y el sistema que lo nota | Determina cuánto tiempo tarda su equipo en enterarse |
| Latencia de procesamiento | Tiempo necesario para comparar, clasificar y filtrar el cambio | Evita que las diferencias crudas se conviertan en ruido |
| Latencia de entrega | Tiempo entre el cambio confirmado y la notificación | Asegura que las alertas lleguen a Slack, correo electrónico o flujos de trabajo rápidamente |
| Latencia de acción | Tiempo entre la alerta y la respuesta del equipo | Depende del contexto, la propiedad y las reglas de escalación |
Muchos equipos se centran solo en la latencia de detección. En la práctica, la latencia de entrega y acción a menudo es el problema más grande. Un cambio oculto en una bandeja de entrada abarrotada no es significativamente más rápido que un cambio encontrado manualmente horas después.
Cobertura de fuentes amplia en páginas, fuentes y API
Las operaciones modernas dependen de más que las páginas web estándar. Un sistema web completo debe poder monitorear varios tipos de fuentes sin obligar a los equipos a crear scripts personalizados para cada formato.
Por ejemplo, los equipos de ingresos pueden preocuparse por las páginas de aterrizaje de los competidores, la disponibilidad de productos y las páginas de precios. Los equipos de cumplimiento pueden rastrear páginas de políticas públicas, términos de servicio, divulgaciones y avisos regulatorios. Los equipos de operaciones pueden depender de páginas de estado de los proveedores, fuentes, documentación de socios o respuestas de API.
Un sistema práctico debe admitir fuentes estructuradas y no estructuradas. Eso incluye el monitoreo de páginas para contenido visible, el seguimiento de fuentes para actualizaciones recurrentes y el seguimiento de API para cambios legibles por máquina. Cuando estos viven en herramientas separadas, los equipos pierden contexto. Cuando viven en un sistema de monitoreo, es más fácil conectar una edición de política, una actualización de fuente y un cambio de API al mismo riesgo operativo.
La cobertura también necesita ser mantenible. Las páginas web cambian de estructura. Las fuentes pueden agregar o eliminar campos. Las API pueden introducir nuevas claves. Un sistema que se rompe cada vez que cambia el diseño de una fuente eventualmente se convertirá en otra carga operativa.
Filtrado de ruido inteligente que protege la atención
La alerta más rápida no siempre es la mejor alerta. Si un sistema notifica a su equipo cada vez que cambia una marca de tiempo, un banner rotativo, un parámetro de seguimiento, una unidad publicitaria, un mensaje de stock o el año del pie de página, la gente dejará de confiar en él.
El filtrado de ruido es una de las partes más importantes de un sistema web moderno porque la atención es finita. El objetivo no es detectar cada diferencia a nivel de byte. El objetivo es identificar los cambios que importan al negocio.
El filtrado útil generalmente incluye normalización y reglas. La normalización ayuda al sistema a ignorar cambios predecibles y de bajo valor, como identificadores dinámicos o cambios de diseño repetidos. Las reglas ayudan a los equipos a definir qué secciones, campos o valores deben desencadenar alertas.
Para las páginas, eso podría significar centrarse en un bloque de precios, un párrafo de cumplimiento, un CTA, una sección de política o un mensaje de disponibilidad. Para las fuentes, podría significar observar nuevas entradas, artículos eliminados o cambios en campos específicos. Para las API, podría significar rastrear valores clave, cambios de esquema, cambios de respuesta o cambios de estado inesperados.
Un buen conjunto de monitoreo también debe permitir umbrales. Un cambio de precio de un centavo puede no requerir la misma acción que un cambio del 15 por ciento. Una actualización de redacción menor puede no necesitar la misma escalación que un cambio en los términos de cancelación. El filtrado debe reflejar cómo funciona su negocio en realidad.
El ritmo de monitoreo debe coincidir con el riesgo comercial
No todas las fuentes merecen la misma frecuencia de monitoreo. Las fuentes de alto riesgo y alto valor deben verificarse con más frecuencia. Las páginas de referencia estables pueden necesitar verificaciones periódicas solo. Coincidir el ritmo con el riesgo ayuda a controlar el costo, reducir el ruido y mantener la atención en lo que más importa.
| Tipo de fuente | Riesgo comercial típico | Mentalidad de ritmo | Propietario probable |
|---|
| Páginas de precios u ofertas | Impacto en los ingresos, presión en los márgenes, respuesta competitiva | Frecuente o en tiempo real para páginas críticas | Ingresos, comercio electrónico, crecimiento |
| Páginas de políticas y términos | Exposición a cumplimiento, obligaciones del cliente, revisión legal | Frecuente enough para respaldar SLA de revisión | Legal, cumplimiento, riesgo |
| Fuentes y API | Rotura operativa, problemas de calidad de datos, fallos de flujo de trabajo | Frecuente para integraciones comerciales críticas | Operaciones, ingeniería, datos |
| Páginas de proveedores o socios | Interrupción del servicio, cambios de proceso, riesgo de dependencia | Basado en la criticidad de la dependencia | Operaciones, compras |
| Páginas de contenido y aterrizaje | Precisión de la campaña, consistencia de la marca, problemas de conversión | Basado en la prioridad de la campaña | Marketing, web, crecimiento |
La clave es evitar un enfoque de monitoreo de un tamaño que se adapte a todos. Una página que afecta los ingresos de la verificación puede necesitar alertas casi en tiempo real. Una página de referencia que cambia dos veces al año puede no necesitarlo. Un sistema moderno debe hacer que sea fácil definir esa diferencia.
La entrega de alertas debe estar diseñada para cómo trabajan los equipos
Una alerta de cambio es útil solo si llega a la persona correcta en el lugar correcto con suficiente contexto para actuar. Esto es donde muchos conjuntos de monitoreo fallan. Deteccionan cambios, pero los entregan de una manera que crea fricción.
Un sistema web moderno debe admitir múltiples rutas de alerta, incluyendo Slack, correo electrónico, webhooks e integraciones de flujo de trabajo. Slack es útil para la visibilidad del equipo y la discusión rápida. El correo electrónico es útil para la notificación duradera y los stakeholders externos. Los webhooks son útiles cuando un cambio necesita desencadenar otro sistema, como un ticket, un flujo de trabajo de incidentes, una actualización de CRM o una automatización interna.
El contexto es tan importante como el canal. Una alerta efectiva debe dejar claro qué cambió, dónde cambió, cuándo cambió y por qué el destinatario la está recibiendo. Si la alerta solo dice que una página cambió, alguien todavía tiene que investigar. Si incluye una diferencia enfocada, detalles de la fuente y contexto histórico, el equipo puede moverse más rápido.
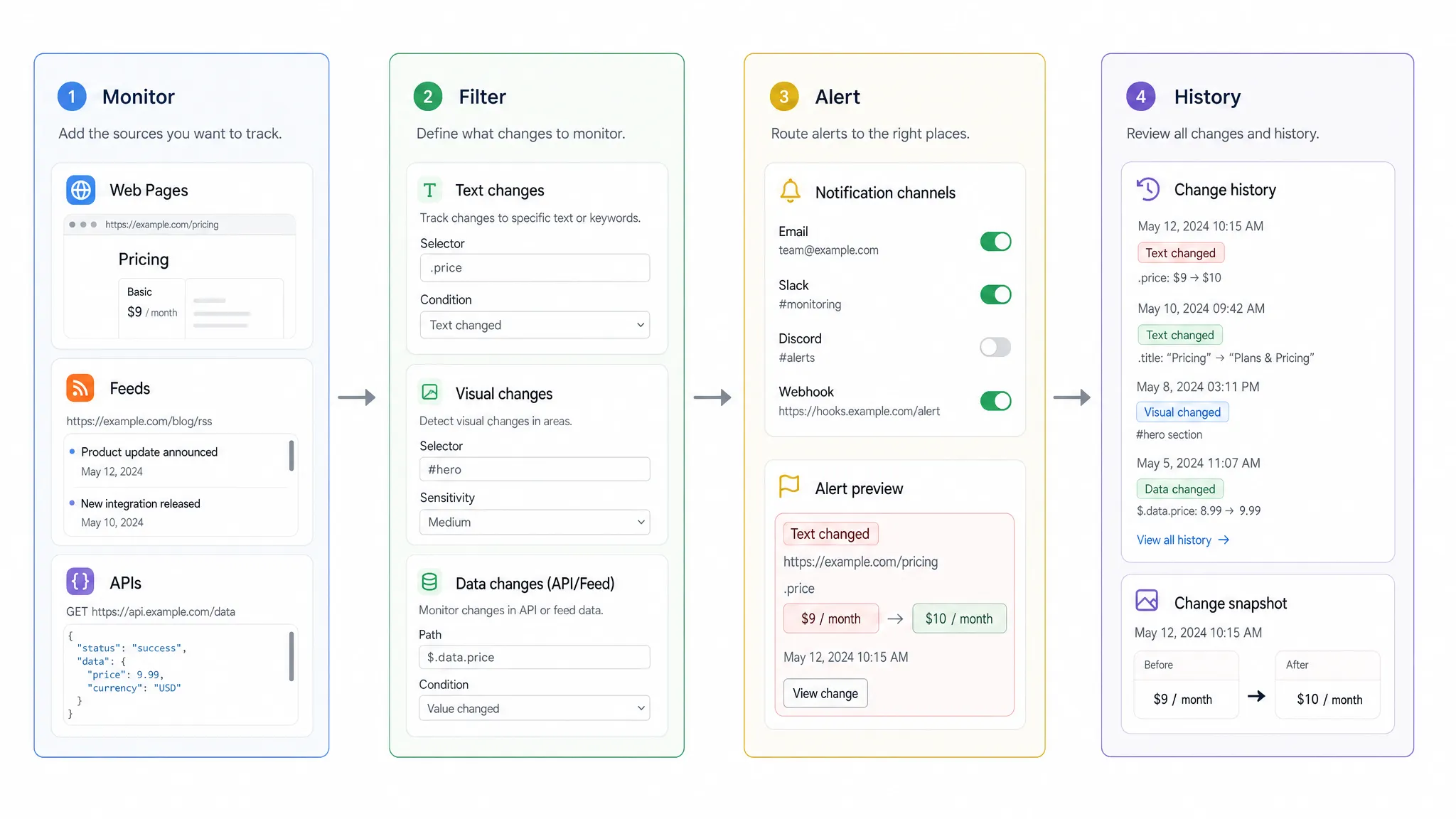
El historial de cambios completo crea responsabilidad
Las alertas rápidas ayudan a los equipos a responder ahora. El historial de cambios ayuda a los equipos a entender qué sucedió más tarde. Ambos son necesarios.
Un sistema web moderno debe preservar un historial confiable de cambios monitoreados. Ese historial es útil para el análisis de causa raíz, las auditorías, las disputas de proveedores, las revisiones de cumplimiento y los informes internos. Sin él, los equipos a menudo terminan confiando en capturas de pantalla, correos electrónicos reenviados o memoria.
El historial de cambios debe responder preguntas prácticas. ¿Cuándo ocurrió el cambio? ¿Cuál era la versión anterior? ¿Qué cambió en la nueva versión? ¿Qué alerta se envió? ¿El cambio fue parte de un patrón recurrente? Estas preguntas se vuelven especialmente importantes cuando un cambio web afecta contratos, exposición regulatoria, decisiones de precios o compromisos del cliente.
Los registros de auditoría también mejoran la confianza. Si un equipo de cumplimiento necesita probar que monitoreó una página de política y revisó los cambios oportunamente, un rastro documentado es mucho más fuerte que un proceso informal.
La gobernanza es importante una vez que el monitoreo se convierte en una tarea crítica
A medida que se expande el monitoreo, la gobernanza se vuelve esencial. Un equipo pequeño puede administrar algunas alertas de manera informal. Una organización más grande necesita controles de acceso, propiedad y disciplina operativa.
El acceso basado en roles ayuda a asegurar que las personas puedan administrar las fuentes y alertas relevantes para su trabajo sin exponer todo a todos. El SSO puede simplificar la administración de acceso para los equipos que ya centralizan la identidad. Las opciones de alojamiento pueden ser importantes para las organizaciones con requisitos de datos regionales o estándares de gobernanza interna.
La gobernanza también incluye la propiedad de alertas. Cada monitor crítico debe tener un propietario claro. Si una página de política cambia, ¿quién la revisa? Si una respuesta de API cambia, ¿quién la investiga? Si una oferta de competidor cambia, ¿quién decide si debe responder? El monitoreo sin propiedad crea conciencia, pero no acción.
Las integraciones convierten la detección en respuesta
Un sistema web moderno no debe ser un callejón sin salida. Debe conectarse a las herramientas donde los equipos ya coordinan el trabajo.
Para las operaciones, eso podría significar crear tickets o desencadenar flujos de trabajo. Para la ingeniería, podría significar enviar payloads estructurados a sistemas internos. Para los equipos de ingresos, podría significar notificar un canal de precios o actualizar un flujo de trabajo de inteligencia competitiva. Para el cumplimiento, podría significar enrutar cambios a una cola de revisión.
Los equipos de marketing también pueden beneficiarse cuando los cambios externos necesitan una respuesta de mercado rápida. Por ejemplo, si un competidor lanza una nueva oferta o cambia su posicionamiento, los equipos pueden enrutar esa información a flujos de trabajo de campaña, y una plataforma impulsada por IA como Needle puede ayudar a las marcas de comercio electrónico a generar y ejecutar activos de marketing de manera más eficiente.
El principio es simple: el sistema de monitoreo debe reducir la distancia entre la detección y la acción. Los webhooks y las integraciones de flujo de trabajo a menudo son el puente que hace que eso sea posible.
Construir versus comprar: qué considerar
Algunos equipos comienzan con scripts. Eso puede funcionar para un pequeño número de páginas o API estables. Pero a medida que el monitoreo se convierte en una tarea crítica, los scripts personalizados a menudo acumulan costos ocultos: mantenimiento, falsos positivos, cambios perdidos, selectores frágiles, enrutamiento de alertas poco claro y sin historial centralizado.
| Requisito | Scripts personalizados | Plataforma de monitoreo moderna |
|---|
| Configuración inicial | Puede ser rápida para fuentes simples | Generalmente más rápida para equipos que monitorean muchos tipos de fuentes |
| Mantenimiento | Requiere tiempo de ingeniería continuo | La plataforma maneja gran parte del flujo de trabajo de monitoreo |
| Filtrado de ruido | Debe construirse y ajustarse manualmente | El filtrado y el control de alertas integrados son esperados |
| Entrega de alertas | A menudo limitada a notificaciones básicas | Entrega de alertas flexible y enrutamiento de flujo de trabajo |