Si una página web importante cambia y nadie se entera hasta que un cliente, regulador, socio o competidor reacciona, el sistema de monitoreo ha fallado. Las alertas tradicionales de sitios web ayudan, pero muchos equipos ahora necesitan algo más operacional: una forma de convertir los cambios web en eventos estructurados que puedan fluir en herramientas internas, colas, paneles y flujos de trabajo.
Esa es la idea central detrás de la monitoreo de sitio web a API. Se monitorean páginas, precios, políticas, feeds y APIs, y luego se entregan los cambios significativos como payloads legibles por API en lugar de confiar solo en capturas de pantalla o alertas de bandeja de entrada.
Si se hace bien, esto da a los equipos de ingresos, cumplimiento, legal, producto y operaciones una capa de señales compartida. Si se hace mal, crea notificaciones ruidosas, scrapers frágiles y automatización que nadie confía. Esta guía pasa por una configuración práctica que mantiene el flujo de trabajo confiable desde la primera URL monitoreada hasta el punto final de la API de recepción.
Qué significa la monitoreo de sitio web a API
La monitoreo de sitio web a API no significa que cada sitio web se convierta mágicamente en una API oficial estable. Si un proveedor o socio ofrece una API documentada que le da los datos que necesita, úsela. Por lo general, será más confiable, más fácil de gobernar y más clara desde un punto de vista legal y operativo.
El caso de uso real es diferente: muchas señales de negocios críticas todavía viven en páginas web públicas, páginas de productos, páginas de precios, documentación, listados de mercado, páginas de políticas, feeds RSS, puntos finales JSON, feeds XML y páginas semiestructuradas que nunca fueron diseñadas para sus sistemas. La monitoreo de sitio web a API convierte los cambios en esas fuentes en eventos estructurados.
| Estilo de monitoreo | Mejor para | Salida | Limitación |
|---|
| Alertas solo humanas | Revisión de bajo volumen y decisiones manuales | Mensaje de correo electrónico o Slack | Difícil de automatizar y medir |
| Monitoreo de cambios visuales | Cambios de diseño, copia, capturas de pantalla y políticas | Vista de diferencia o instantánea | Puede ser ruidoso sin filtrado |
| Extracción estructurada | Precios, disponibilidad, términos, campos, tablas | Valores normalizados | Requiere selectores claros o reglas de análisis |
| Flujo de trabajo de sitio web a API | Automatización operativa y actualizaciones de sistema | Webhook o payload de API | Necesita esquema, enrutamiento y gobernanza |
Una buena configuración combina estos enfoques. Algunos cambios deben ir a los humanos para revisión. Otros deben crear tickets, actualizar registros internos, desencadenar un flujo de trabajo de ingresos o notificar un servicio descendente de inmediato.
Comience con la decisión, no con la URL
La forma más rápida de crear una configuración de monitoreo frágil es comenzar con una lista gigante de URLs. Un mejor punto de partida es la decisión que su equipo necesita tomar cuando algo cambia.
Pregúntese: si esta página cambia, ¿quién actúa, cómo de rápido y qué información necesita?
Por ejemplo, un equipo de ingresos podría monitorear páginas de precios de competidores porque una caída de precio debería desencadenar una actualización de habilitación de ventas. Un equipo de cumplimiento podría monitorear páginas de políticas de proveedores porque una nueva redacción podría afectar compromisos de clientes. Un equipo de operaciones de productos podría monitorear la documentación de la API porque un campo obsoleto podría romper una integración.
Una monitoreo de sitio web a API sólida comienza con una señal de negocio como:
- Un competidor cambia un precio público, límite de plan o término de empaque
- Un proveedor actualiza una política de privacidad, SLA, política de uso aceptable o página de seguridad
- Un listado de mercado agrega, elimina o cambia un producto
- Un feed publica un nuevo registro que debería entrar en un flujo de trabajo interno
- Una respuesta de API cambia de una manera que afecta sistemas descendentes
Una vez que la decisión esté clara, la configuración técnica se vuelve más fácil. Sabes qué extraer, con qué frecuencia verificar, qué cambios son ruido y dónde debería ir el evento resultante.
Cree un mapa de fuentes a través de páginas, feeds y APIs
La mayoría de los equipos descubren que su paisaje de monitoreo es más amplio de lo esperado. Un solo proceso de negocio puede depender de una página de precios, una página de documentación, una página de estado, un punto final JSON y un feed de socio.
Cree un mapa de fuentes antes de configurar alertas. Al menos, capture la URL, propietario, tipo de fuente, razón de negocio, frecuencia de cambio esperada y tiempo de respuesta requerido. Esto evita que el monitoreo se convierta en una colección de verificaciones desconectadas.
| Tipo de fuente | Señal de ejemplo | Enfoque de monitoreo recomendado | Destino típico |
|---|
| Página de precios | Cambios de precio o descuento | Extracción de precios más vista de diferencia | Canal de ingresos o flujo de trabajo de CRM |
| Página de políticas | Cambios de redacción legal o fecha efectiva | Diferencia de texto con filtrado de ruido | Cola de revisión de cumplimiento |
| Página de productos | Cambios de disponibilidad, características o especificaciones | Seguimiento de campos estructurados | Alerta de operaciones o ventas |
| Feed RSS o XML | Nuevo elemento o elemento eliminado | Monitoreo de feed | Flujo de trabajo de contenido o catálogo |
| Punto final de API | Cambio de campo, estado o respuesta | Monitoreo de respuesta de API | Flujo de trabajo de ingeniería o incidente |
Si necesita un marco más amplio para organizar fuentes, la guía de DiffHook sobre cómo detectar cambios de sitio en páginas, feeds y APIs es un compañero útil para este proceso de configuración.
La clave es evitar tratar todas las fuentes de la misma manera. Una página de precios de alto impacto puede necesitar detección rápida y enrutamiento automatizado. Un feed de blog de bajo riesgo puede necesitar solo un resumen diario. Una página de políticas puede necesitar historia de cambios completa y revisión humana antes de que se tome cualquier acción.
Defina el esquema de eventos antes de monitorear
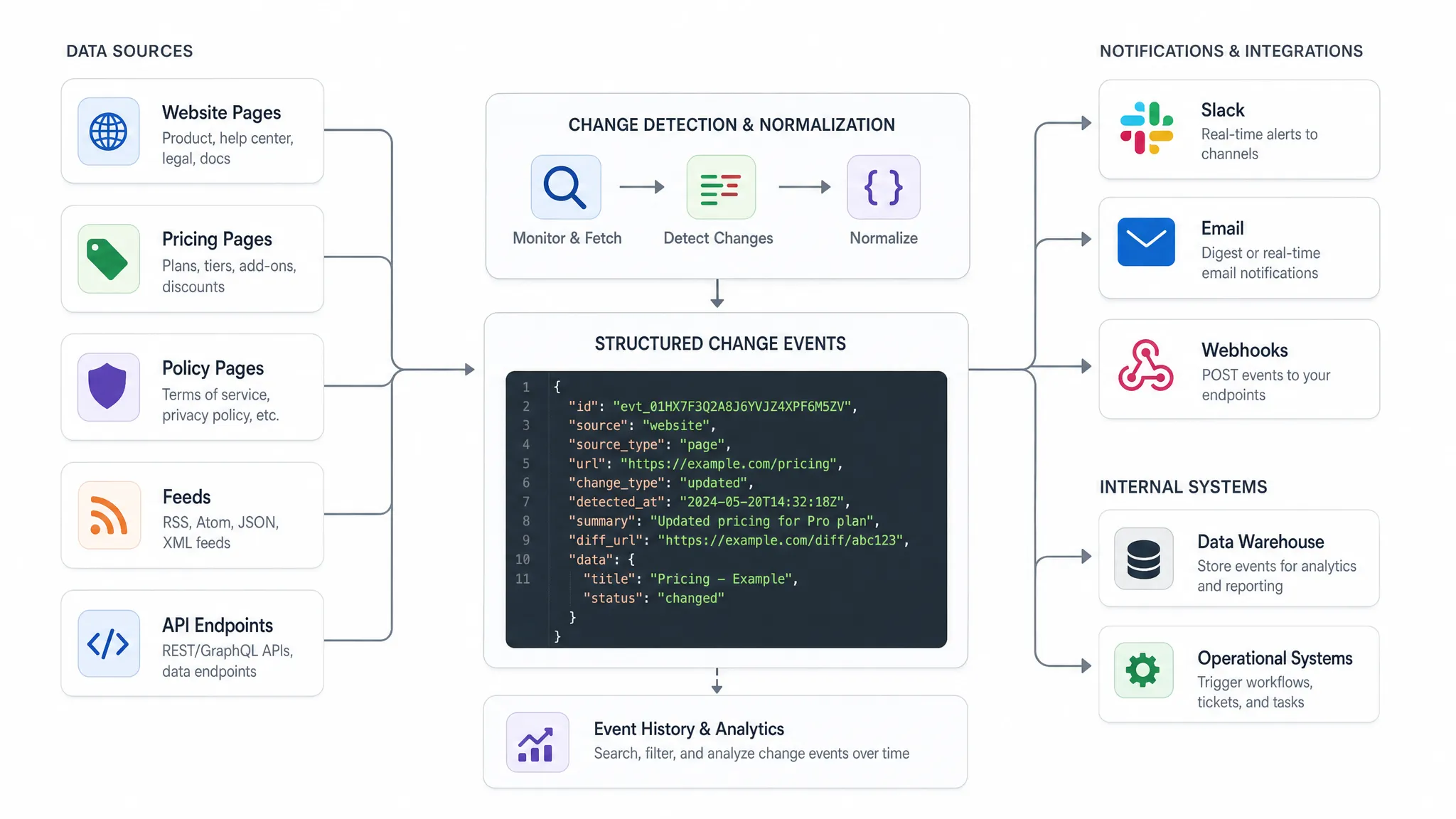
La API de recepción no debería recibir un mensaje vago que diga "algo cambió". Debería recibir un evento estructurado con suficiente contexto para actuar.
Un esquema de eventos práctico suele responder a cinco preguntas: qué cambió, dónde cambió, cuándo se detectó, cuán importante es y qué debería suceder a continuación.
| Campo | Propósito |
|---|
event_id | Identificador único para deduplicación y auditoría |
source_url | La página, feed o punto final monitoreado |
source_type | Página, feed, API, precio, política o categoría personalizada |
change_type | Cambio de precio, cambio de texto, elemento agregado, elemento eliminado, respuesta cambiada |
old_value y new_value | Valores estructurados antes y después, cuando estén disponibles |
detected_at | Marca de tiempo para respuesta operativa y informes |
severity | Prioridad de negocio como baja, media, alta o crítica |
diff_reference | Enlace o identificador para revisar la historia de cambios completa |
owner | Equipo o sistema responsable del próximo paso |
Aquí hay un ejemplo de payload simplificado:
{
"event_id": "chg_20260630_184522",
"source_url": "https://example-source.com/pricing",
"source_type": "pricing_page",
"change_type": "price_change",
"detected_at": "2026-06-30T18:45:22Z",
"old_value": "$99/month",
"new_value": "$89/month",
"severity": "high",
"owner": "revenue_ops"
}
No todas las fuentes producirán todos los campos. Un cambio de página de políticas puede tener una diferencia de texto en lugar de un precio viejo y nuevo. Un punto final de API puede incluir un camino JSON cambiado. El punto es definir el contrato temprano para que los sistemas descendentes puedan procesar eventos de manera consistente.
Configure reglas de monitoreo que separan la señal del ruido
Las páginas web cambian constantemente. Los banners de cookies, las marcas de tiempo, los testimonios rotativos, la personalización, los parámetros de seguimiento, las fotos de stock, los anuncios y las variantes de prueba A/B pueden crear falsos positivos.
El filtrado de ruido es lo que hace que la monitoreo de sitio web a API sea usable. Sin él, los equipos dejan de confiar en las alertas y la automatización se deshabilita.
Un buen filtrado suele incluir varias capas. Primero, monitoree la parte más relevante de la página en lugar de todo el DOM cuando sea posible. Segundo, normalice los cambios de formato como espacios en blanco, mayúsculas o formato de moneda cuando no sean significativos. Tercero, aplique umbrales para que los pequeños ediciones de copia no desencadenen flujos de trabajo de alta severidad. Cuarto, debote los cambios repetidos para que una página inestable no inunde su API de recepción.
Esto es especialmente importante para flujos de trabajo operativos. Una notificación de Slack puede ser ignorada si es ruidosa. Un evento de API puede crear un ticket, actualizar un registro o desencadenar un proceso descendente, por lo que los falsos positivos tienen un costo real.
DiffHook está construido alrededor de este tipo de monitoreo práctico, incluyendo detección de cambios en tiempo real, seguimiento de páginas, feeds y APIs, alertas de cambios de precios, filtrado de ruido inteligente, notificaciones de Slack y correo electrónico, webhooks, integraciones de flujo de trabajo y historia de cambios completa.
Enrute alertas y eventos de API de manera diferente
Un error común es enviar todos los cambios a todos los canales. Los humanos necesitan contexto y priorización. Los sistemas necesitan datos estructurados y entrega predecible. Esas son relacionadas, pero no son lo mismo.
Use alertas humanas para decisiones de revisión intensiva, como cambios de políticas, actualizaciones de redacción legal y movimientos de competidores de alto impacto. Use eventos de API o webhooks cuando el cambio debería entrar en un flujo de trabajo automáticamente, como crear un ticket, actualizar un registro interno, notificar a un propietario de cuenta o iniciar un proceso de aprobación.
Si está decidiendo cuándo las alertas son suficientes y cuándo necesita entrega estructurada, el artículo de DiffHook sobre cuándo necesita una API para sitios web, no solo alertas cubre el punto de decisión en más profundidad.
La regla práctica es simple: si el destinatario es una persona, optimice para claridad. Si el destinatario es un sistema, optimice para esquema, idempotencia y confiabilidad.
Diseñe el punto final de recepción para confiabilidad
Una vez que los cambios se entregan como eventos de API, su sistema de recepción se convierte en parte del flujo de trabajo de monitoreo. Trátelo como infraestructura de producción.
Su punto final debería aceptar solo los payloads que entiende, validar campos requeridos, almacenar el evento antes de realizar un procesamiento pesado y devolver una respuesta de éxito solo después de que el evento sea aceptado de manera segura. Si el procesamiento descendente falla, el evento aún debería ser recuperable desde su propia cola o base de datos.
Construya para estos patrones de confiabilidad:
- Idempotencia, para que el mismo evento pueda ser reintento sin crear tickets o registros duplicados
- Autenticación, utilizando los métodos de seguridad disponibles en sus herramientas de monitoreo y flujo de trabajo
- Códigos de respuesta claros, para que los fallos de entrega puedan ser reintentados o investigados
- Registro, para que cada evento recibido pueda ser rastreado hasta una fuente y marca de tiempo
- Esquemas de versiones, para que pueda agregar campos sin romper consumidores
También decida cómo se manejan los fallos. Si el receptor está abajo, ¿debería el plataforma de monitoreo reintento? ¿Debería un humano ser notificado después de fallos repetidos? ¿Deberían los cambios críticos también ir a Slack o correo electrónico como respaldo? Estas decisiones deberían tomarse antes del primer incidente.
Pruebe con cambios controlados antes de ir en vivo
No espere a que un cambio real de precio de competidor o actualización de política para descubrir si el flujo de trabajo funciona. Ejecute pruebas controladas antes de que la configuración de monitoreo se vuelva operativa.
| Prueba | Qué verificar | Fallo para vigilar |
|---|
| Cambio de texto de ejemplo | La sección correcta es monitoreada | El ruido de página completa desencadena una alerta |
| Cambio de precio de ejemplo | Los valores viejos y nuevos se extraen correctamente | La moneda, el descuento o el formato es mal leído |
| Entrega duplicada | El receptor maneja reintentos de manera segura | Se crean tickets o registros duplicados |
| Cambio de baja severidad | El enrutamiento coincide con la prioridad | Todos los cambios menores se convierten en urgentes |
| Fallo del punto final | El manejo de fallos funciona | Los eventos desaparecen sin revisión |
| Revisión de auditoría | La historia de cambios está disponible | Los equipos no pueden probar qué cambió |
Las pruebas deberían incluir tanto usuarios técnicos como de negocio. Los ingenieros pueden confirmar la entrega, la validación del esquema y el comportamiento de reintento. Los propietarios de negocio pueden confirmar si el evento contiene enough contexto para actuar.
