Se una pagina web importante cambia e nessuno se ne accorge fino a quando un cliente, un regolatore, un partner o un concorrente reagisce, il sistema di monitoraggio ha fallito. Gli avvisi tradizionali dei siti web aiutano, ma molte squadre hanno ora bisogno di qualcosa di più operativo: un modo per trasformare i cambiamenti web in eventi strutturati che possano fluire negli strumenti interni, nelle code, nei dashboard e nei flussi di lavoro.
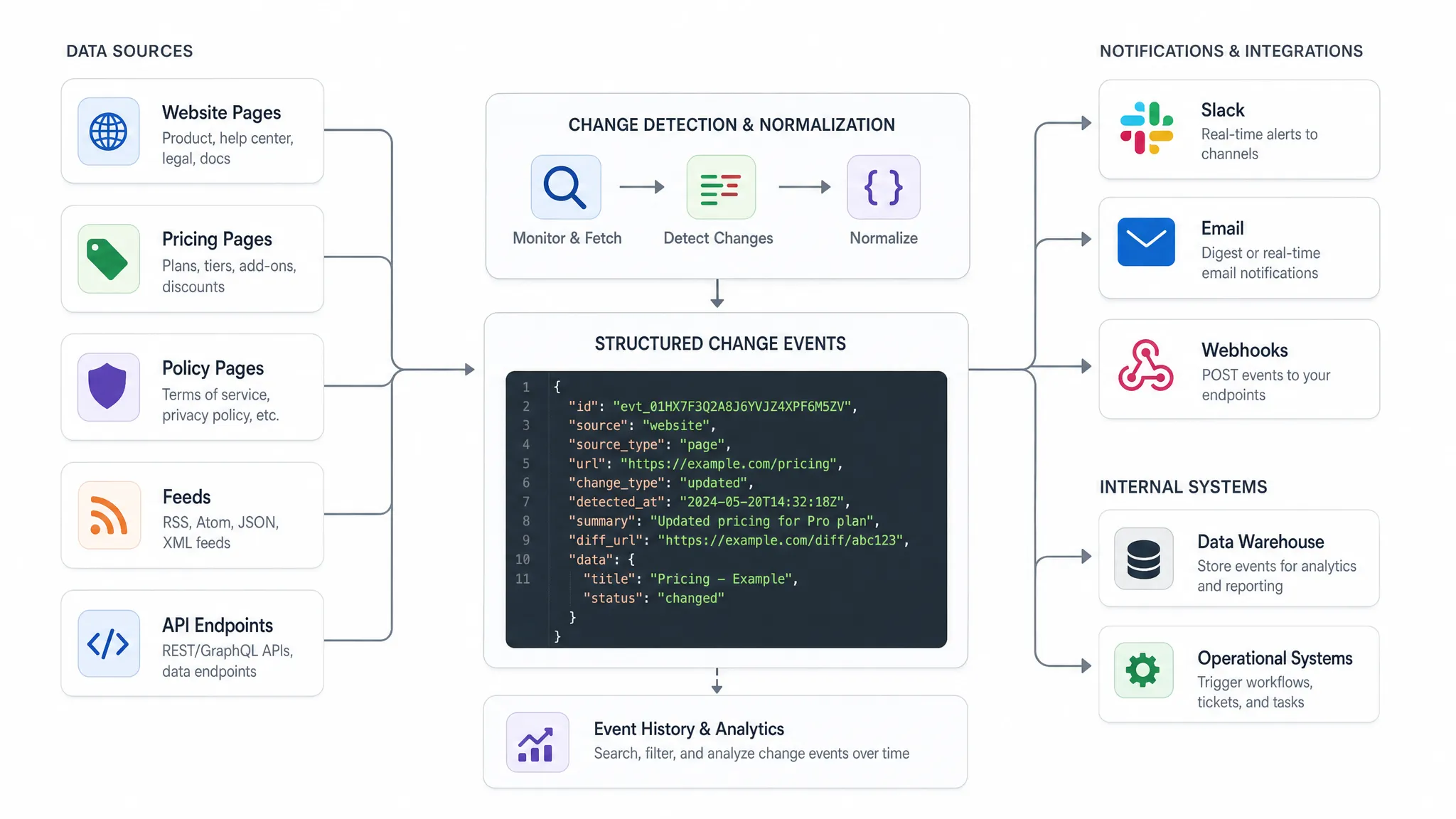
Questo è l'idea fondamentale dietro il monitoraggio da sito web a API. Si monitorano pagine, prezzi, politiche, feed e API, quindi si consegnano i cambiamenti significativi come payload leggibili dall'API invece di affidarsi solo a screenshot o avvisi di posta elettronica.
Se fatto bene, ciò dà ai team di revenue, conformità, legale, prodotto e operazioni un livello di segnale condiviso. Se fatto male, crea notifiche rumorose, scraper fragili e automazione che nessuno si fida. Questa guida passa attraverso una configurazione pratica che mantiene il flusso di lavoro affidabile dal primo URL monitorato al punto di arrivo dell'API.
Cosa significa il monitoraggio da sito web a API
Il monitoraggio da sito web a API non significa che ogni sito web diventi magicamente un'API stabile e ufficiale. Se un fornitore o un partner offre un'API documentata che fornisce i dati necessari, utilizzarla. Sarà solitamente più affidabile, più facile da governare e più chiara da un punto di vista legale e operativo.
Il caso d'uso reale è diverso: molti segnali aziendali critici vivono ancora su pagine web pubbliche, pagine di prodotto, pagine di prezzo, documentazione, elenchi di mercato, pagine di politica, feed RSS, endpoint JSON, feed XML e pagine semi-strutturate che non sono state progettate per i sistemi. Il monitoraggio da sito web a API trasforma i cambiamenti in queste fonti in eventi strutturati.
| Stile di monitoraggio | Migliore per | Output | Limitazione |
|---|
| Avvisi umani | Revisione a basso volume e decisioni manuali | Messaggio di posta elettronica o Slack | Difficile da automatizzare e misurare |
| Monitoraggio dei cambiamenti visivi | Layout, copia, screenshot e cambiamenti di politica | Vista differenziale o snapshot | Può essere rumoroso senza filtraggio |
| Estrazione strutturata | Prezzi, disponibilità, termini, campi, tabelle | Valori normalizzati | Richiede selettori chiari o regole di parsing |
| Flusso di lavoro da sito web a API | Automazione operativa e aggiornamenti di sistema | Webhook o payload API | Richiede schema, routing e governance |
Una buona configurazione combina questi approcci. Alcuni cambiamenti dovrebbero andare agli umani per la revisione. Altri dovrebbero creare biglietti, aggiornare record interni, attivare un flusso di lavoro di revenue o notificare un servizio a valle immediatamente.
Iniziare con la decisione, non con l'URL
Il modo più veloce per creare una configurazione di monitoraggio fragile è iniziare con una lunga lista di URL. Un punto di partenza migliore è la decisione che il team deve prendere quando qualcosa cambia.
Chiedi: se questa pagina cambia, chi agisce, come rapidamente e quale informazione ha bisogno?
Ad esempio, un team di revenue potrebbe monitorare le pagine di prezzo dei concorrenti perché una riduzione del prezzo dovrebbe attivare un aggiornamento di abilitazione delle vendite. Un team di conformità potrebbe monitorare le pagine di politica dei fornitori perché nuove parole potrebbero influenzare gli impegni dei clienti. Un team di operazioni di prodotto potrebbe monitorare la documentazione dell'API perché un campo deprecato potrebbe interrompere un'integrazione.
Un forte monitoraggio da sito web a API inizia con un segnale aziendale come:
- Un concorrente cambia un prezzo pubblico, un limite di piano o un termine di confezionamento
- Un fornitore aggiorna una politica di privacy, un accordo di livello di servizio, una politica di utilizzo accettabile o una pagina di sicurezza
- Un elenco di mercato aggiunge, rimuove o cambia un prodotto
- Un feed pubblica un nuovo record che dovrebbe entrare in un flusso di lavoro interno
- Una risposta API cambia in modo da influenzare i sistemi a valle
Una volta che la decisione è chiara, la configurazione tecnica diventa più facile. Si sa cosa estrarre, come spesso controllare, quali cambiamenti sono rumore e dove l'evento risultante dovrebbe andare.
Creare una mappa delle fonti tra pagine, feed e API
La maggior parte delle squadre scopre che il loro paesaggio di monitoraggio è più ampio del previsto. Un singolo processo aziendale può dipendere da una pagina di prezzo, una pagina di documentazione, una pagina di stato, un endpoint JSON e un feed di partner.
Creare una mappa delle fonti prima di configurare gli avvisi. Almeno, catturare l'URL, il proprietario, il tipo di fonte, il motivo aziendale, la frequenza di cambio prevista e il tempo di risposta richiesto. Ciò impedisce che il monitoraggio diventi una raccolta di controlli non collegati.
| Tipo di fonte | Segnale di esempio | Approccio di monitoraggio consigliato | Destinazione tipica |
|---|
| Pagina di prezzo | Cambiamenti di prezzo o sconto | Estrazione del prezzo più differenza di pagina | Canale di revenue o flusso di lavoro CRM |
| Pagina di politica | Cambiamenti di parole legali o date di entrata in vigore | Differenza di testo con filtraggio del rumore | Coda di revisione della conformità |
| Pagina di prodotto | Disponibilità, caratteristiche o specifiche | Tracciamento di campi strutturati | Allarme operativo o di vendita |
| Feed RSS o XML | Nuovo elemento o elemento rimosso | Monitoraggio del feed | Flusso di lavoro di contenuto o catalogo |
| Endpoint API | Cambiamento di campo, stato o risposta | Monitoraggio della risposta API | Flusso di lavoro di ingegneria o incidente |
Se si necessita di un quadro più ampio per organizzare le fonti, la guida di DiffHook su come rilevare i cambiamenti del sito tra pagine, feed e API è un utile compagno di questo processo di configurazione.
La chiave è evitare di trattare tutte le fonti allo stesso modo. Una pagina di prezzo ad alto impatto può richiedere rilevamento rapido e routing automatizzato. Un feed di blog a basso rischio può solo richiedere un riepilogo giornaliero. Una pagina di politica può richiedere la cronologia completa dei cambiamenti e la revisione umana prima di qualsiasi azione.
Definire lo schema degli eventi prima di monitorare
L'API di destinazione non dovrebbe ricevere un messaggio vago che dice "qualcosa è cambiato". Dovrebbe ricevere un evento strutturato con sufficiente contesto per agire.
Uno schema di eventi pratico risponde solitamente a cinque domande: cosa è cambiato, dove è cambiato, quando è stato rilevato, quanto è importante e cosa dovrebbe succedere dopo.
| Campo | Scopo |
|---|
event_id | Identificatore univoco per la deduplicazione e la tracciabilità |
source_url | La pagina, il feed o l'endpoint monitorato |
source_type | Pagina, feed, API, prezzo, politica o categoria personalizzata |
change_type | Cambiamento di prezzo, cambiamento di testo, elemento aggiunto, elemento rimosso, risposta cambiata |
old_value e new_value | Valori strutturati prima e dopo, quando disponibili |
detected_at | Timestamp per la risposta operativa e la segnalazione |
severity | Priorità aziendale come bassa, media, alta o critica |
diff_reference | Collegamento o identificatore per la revisione della cronologia completa dei cambiamenti |
owner | Team o sistema responsabile del passo successivo |
Ecco un esempio di payload semplificato:
{
"event_id": "chg_20260630_184522",
"source_url": "https://example-source.com/pricing",
"source_type": "pricing_page",
"change_type": "price_change",
"detected_at": "2026-06-30T18:45:22Z",
"old_value": "$99/month",
"new_value": "$89/month",
"severity": "high",
"owner": "revenue_ops"
}
Non tutte le fonti produrranno ogni campo. Un cambiamento di pagina di politica può avere una differenza di testo invece di un prezzo vecchio e nuovo. Un endpoint API può includere un percorso JSON cambiato. Il punto è definire il contratto presto in modo che i sistemi a valle possano elaborare gli eventi in modo coerente.
Configurare regole di monitoraggio che separano il segnale dal rumore
Le pagine web cambiano costantemente. I banner dei cookie, i timestamp, le testimonianze rotanti, la personalizzazione, i parametri di tracciamento, le foto di stock, gli annunci e le varianti di test A/B possono tutti creare falsi positivi.
Il filtraggio del rumore è ciò che rende il monitoraggio da sito web a API utilizzabile. Senza di esso, le squadre smettono di fidarsi degli avvisi e l'automazione viene disabilitata.
Un buon filtraggio solitamente include più strati. In primo luogo, monitorare la parte più rilevante della pagina invece di tutto il DOM quando possibile. In secondo luogo, normalizzare i cambiamenti di formattazione come spaziature, maiuscole o formattazione di valuta quando non sono significativi. In terzo luogo, applicare soglie in modo che piccoli cambiamenti di copia non attivino flussi di lavoro ad alta priorità. In quarto luogo, debouncare i cambiamenti ripetuti in modo che una pagina instabile non inondi l'API di destinazione.
Ciò è particolarmente importante per i flussi di lavoro operativi. Una notifica di Slack può essere ignorata se è rumorosa. Un evento API potrebbe creare un biglietto, aggiornare un record o attivare un processo a valle, quindi i falsi positivi hanno un costo reale.
DiffHook è costruito intorno a questo tipo di monitoraggio pratico, compresa la rilevazione dei cambiamenti in tempo reale, il tracciamento di pagine, feed e API, gli avvisi di cambiamenti di prezzo, il filtraggio del rumore intelligente, le notifiche di Slack e posta elettronica, i webhooks, le integrazioni del flusso di lavoro e la cronologia completa dei cambiamenti.
Route avvisi e eventi API in modo diverso
Un errore comune è inviare ogni cambiamento a ogni canale. Gli umani hanno bisogno di contesto e priorità. I sistemi hanno bisogno di dati strutturati e consegna prevedibile. Queste sono correlate, ma non sono la stessa cosa.
Utilizzare gli avvisi umani per le decisioni di revisione, come i cambiamenti di politica, gli aggiornamenti della formulazione legale e le mosse dei concorrenti ad alto impatto. Utilizzare gli eventi API o i webhooks quando il cambiamento dovrebbe entrare in un flusso di lavoro automaticamente, come creare un biglietto, aggiornare un database, notificare un proprietario di account o avviare un processo di approvazione.
Se si sta decidendo quando gli avvisi sono sufficienti e quando è necessario un delivery strutturato, l'articolo di DiffHook su quando è necessario un'API per i siti web, non solo avvisi copre il punto di decisione in più dettaglio.
La regola pratica è semplice: se il destinatario è una persona, ottimizzare per la chiarezza. Se il destinatario è un sistema, ottimizzare per lo schema, l'idempotenza e l'affidabilità.
Progettare il punto di arrivo per l'affidabilità
Una volta che i cambiamenti sono consegnati come eventi API, il sistema di destinazione diventa parte del flusso di lavoro di monitoraggio. Trattarlo come infrastruttura di produzione.
Il punto di arrivo dovrebbe accettare solo i payload che comprende, convalidare i campi richiesti, archiviare l'evento prima di eseguire un'elaborazione pesante e restituire una risposta di successo solo dopo che l'evento è stato accettato in modo sicuro. Se l'elaborazione a valle fallisce, l'evento dovrebbe comunque essere recuperabile dalla coda o dal database proprio.
Costruire per questi modelli di affidabilità:
- Idempotenza, in modo che lo stesso evento possa essere ritentato senza creare biglietti o record duplicati
- Autenticazione, utilizzando i metodi di sicurezza disponibili negli strumenti di monitoraggio e flusso di lavoro
- Codici di risposta chiari, in modo che i fallimenti di consegna possano essere ritentati o investigati
- Registrazione, in modo che ogni evento ricevuto possa essere tracciato a una fonte e a un timestamp
- Schema versionato, in modo che si possano aggiungere campi senza rompere i consumatori
Decidere anche come vengono gestiti i fallimenti. Se il ricevitore è down, il piattaforma di monitoraggio dovrebbe ritentare? Dovrebbe essere notificato un umano dopo fallimenti ripetuti? I cambiamenti critici dovrebbero anche andare a Slack o posta elettronica come fallback? Queste decisioni dovrebbero essere prese prima del primo incidente.
Testare con cambiamenti controllati prima di andare live
Non aspettare un reale cambiamento di prezzo di un concorrente o un aggiornamento di politica per scoprire se il flusso di lavoro funziona. Eseguire test controllati prima che la configurazione di monitoraggio diventi operativa.
| Test | Cosa verificare | Fallimento da guardare |
|---|
| Cambiamento di testo di esempio | La sezione giusta è monitorata | Il rumore di pagina completa attiva un avviso |
| Cambiamento di prezzo di esempio | I valori vecchi e nuovi sono estratti correttamente | La valuta, lo sconto o il formattaggio è mal letto |
| Consegna doppia | Il ricevitore gestisce le ritentate in modo sicuro | Vengono creati biglietti o record duplicati |
| Cambiamento a bassa priorità | L'instradamento corrisponde alla priorità | Ogni piccolo cambiamento diventa urgente |
| Guasto dell'endpoint | La gestione dei fallimenti funziona | Gli eventi scompaiono senza revisione |
| Revisione dell'audit | La cronologia dei cambiamenti è disponibile | Le squadre non possono dimostrare cosa è cambiato |
I test dovrebbero includere sia utenti tecnici che aziendali. Gli ingegneri possono confermare la consegna, la convalida dello schema e il comportamento di ritentata. I proprietari aziendali possono confermare se l'evento contiene le informazioni necessarie per agire.
