Si une page Web importante change et que personne ne le remarque jusqu'à ce qu'un client, un régulateur, un partenaire ou un concurrent réagisse, le système de surveillance a échoué. Les alertes traditionnelles de site Web aident, mais de nombreuses équipes ont maintenant besoin de quelque chose de plus opérationnel : un moyen de convertir les changements Web en événements structurés qui peuvent s'intégrer dans les outils internes, les files d'attente, les tableaux de bord et les flux de travail.
C'est l'idée centrale derrière la surveillance de site Web à API. Vous surveillez les pages, les prix, les politiques, les flux et les API, puis livrez les changements significatifs sous forme de charges utiles lisibles par API au lieu de vous fier uniquement aux captures d'écran ou aux alertes de boîte de réception.
Bien fait, cela donne aux équipes de revenus, de conformité, juridiques, de produits et d'exploitation une couche de signal partagée. Mal fait, cela crée des notifications bruyantes, des scrapers fragiles et une automatisation que personne ne fait confiance. Ce guide présente une configuration pratique qui maintient le flux de travail fiable à partir de la première URL surveillée jusqu'au point de terminaison de l'API de réception.
Ce que signifie la surveillance de site Web à API
La surveillance de site Web à API ne signifie pas que chaque site Web devient magiquement une API officielle stable. Si un fournisseur ou un partenaire propose une API documentée qui vous donne les données dont vous avez besoin, utilisez-la. Elle sera généralement plus fiable, plus facile à gouverner et plus claire d'un point de vue juridique et opérationnel.
Le cas d'utilisation réel est différent : de nombreux signaux commerciaux critiques vivent toujours sur des pages Web publiques, des pages de produits, des pages de tarification, de la documentation, des listes de marché, des pages de politiques, des flux RSS, des points de terminaison JSON, des flux XML et des pages semi-structurées qui n'ont jamais été conçues pour vos systèmes. La surveillance de site Web à API convertit les changements de ces sources en événements structurés.
| Style de surveillance | Meilleur pour | Sortie | Limitation |
|---|
| Alertes humaines uniquement | Examen à faible volume et décisions manuelles | Message électronique ou message Slack | Difficile à automatiser et à mesurer |
| Surveillance des changements visuels | Mise en page, copie, captures d'écran et changements de politiques | Vue de différence ou instantané | Peut être bruyant sans filtrage |
| Extraction structurée | Prix, disponibilité, conditions, champs, tableaux | Valeurs normalisées | Nécessite des sélecteurs clairs ou des règles d'analyse |
| Flux de travail de site Web à API | Automatisation opérationnelle et mises à jour de système | Charge utile Webhook ou API | Nécessite un schéma, un routage et une gouvernance |
Une bonne configuration combine ces approches. Certains changements doivent aller aux humains pour examen. D'autres doivent créer des tickets, mettre à jour des enregistrements internes, déclencher un flux de travail de revenus ou notifier un service en aval immédiatement.
Commencez par la décision, pas l'URL
Le moyen le plus rapide de créer une configuration de surveillance fragile est de commencer par une grande liste d'URL. Un meilleur point de départ est la décision que votre équipe doit prendre lorsque quelque chose change.
Demandez : si cette page change, qui agit, à quelle vitesse et quelle information ont-ils besoin ?
Par exemple, une équipe de revenus peut surveiller les pages de tarification des concurrents car une baisse de prix devrait déclencher une mise à jour d'activation des ventes. Une équipe de conformité peut surveiller les pages de politiques des fournisseurs car de nouveaux libellés pourraient affecter les engagements des clients. Une équipe de produits et d'exploitation peut surveiller la documentation de l'API car un champ déprécié pourrait rompre une intégration.
Une surveillance solide de site Web à API commence par un signal commercial tel que :
- Un concurrent change un prix public, une limite de plan ou un terme d'emballage
- Un fournisseur met à jour une politique de confidentialité, un SLA, une politique d'utilisation acceptable ou une page de sécurité
- Une liste de marché ajoute, supprime ou modifie un produit
- Un flux publie un nouvel enregistrement qui devrait entrer dans un flux de travail interne
- Une réponse d'API change d'une manière qui affecte les systèmes en aval
Une fois la décision claire, la configuration technique devient plus facile. Vous savez ce que vous devez extraire, à quelle fréquence vous devez vérifier, quels changements sont du bruit et où l'événement résultant devrait aller.
Créez une carte de sources à travers les pages, les flux et les API
La plupart des équipes découvrent que leur paysage de surveillance est plus large que prévu. Un seul processus commercial peut dépendre d'une page de tarification, d'une page de documentation, d'une page de statut, d'un point de terminaison JSON et d'un flux de partenariat.
Créez une carte de sources avant de configurer les alertes. Au minimum, capturez l'URL, le propriétaire, le type de source, la raison commerciale, la fréquence de changement attendue et le temps de réponse requis. Cela empêche la surveillance de devenir une collection de vérifications non connectées.
| Type de source | Exemple de signal | Approche de surveillance recommandée | Destination typique |
|---|
| Page de tarification | Changements de prix ou de remise | Extraction de prix plus différence de page | Canal de revenus ou flux de travail CRM |
| Page de politiques | Changements de libellés juridiques ou de date d'entrée en vigueur | Différence de texte avec filtrage de bruit | File d'attente d'examen de conformité |
| Page de produits | Disponibilité, fonctionnalités ou spécifications | Suivi de champs structurés | Alertes d'exploitation ou de ventes |
| Flux RSS ou XML | Nouvel article ou article supprimé | Surveillance de flux | Flux de travail de contenu ou de catalogue |
| Point de terminaison d'API | Changement de champ, de statut ou de réponse | Surveillance de réponse d'API | Flux de travail d'ingénierie ou d'incident |
Si vous avez besoin d'un cadre plus large pour organiser les sources, le guide de DiffHook sur la détection des changements de site à travers les pages, les flux et les API est un compagnon utile pour ce processus de configuration.
La clé est d'éviter de traiter toutes les sources de la même manière. Une page de tarification à forte incidence peut nécessiter une détection rapide et un routage automatisé. Un flux de blog à faible risque peut ne nécessiter qu'un résumé quotidien. Une page de politiques peut nécessiter une historique complète des changements et un examen humain avant toute action.
Définissez le schéma d'événement avant de surveiller
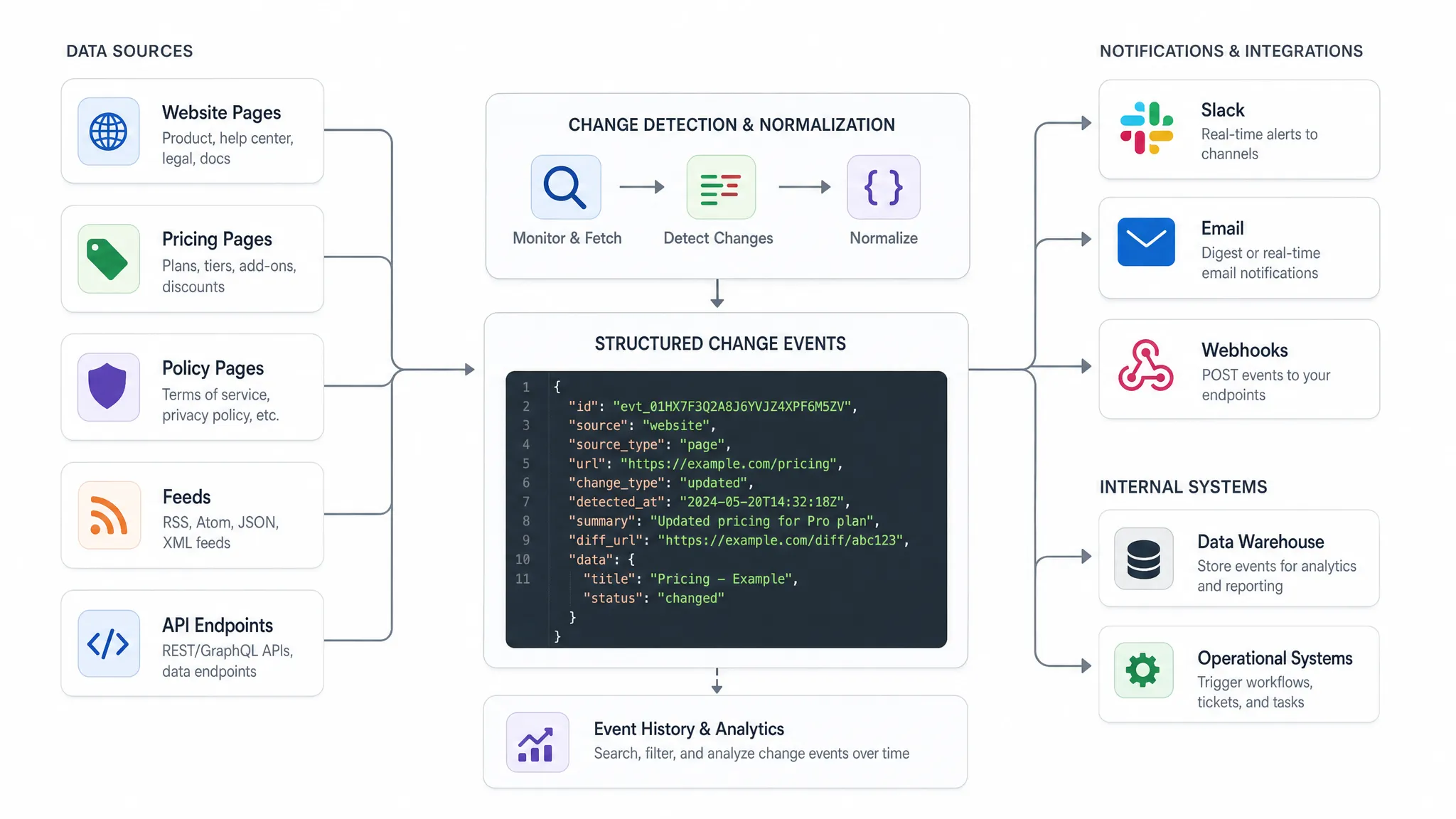
L'API de réception ne devrait pas recevoir un message vague qui indique « quelque chose a changé ». Il devrait recevoir un événement structuré avec suffisamment de contexte pour agir.
Un schéma d'événement pratique répond généralement à cinq questions : ce qui a changé, où cela a changé, quand cela a été détecté, à quel point cela est important et ce qui devrait se passer ensuite.
| Champ | Objectif |
|---|
event_id | Identifiant unique pour la déduplication et la traçabilité |
source_url | La page, le flux ou le point de terminaison surveillé |
source_type | Page, flux, API, prix, politique ou catégorie personnalisée |
change_type | Changement de prix, changement de texte, article ajouté, article supprimé, réponse modifiée |
old_value et new_value | Valeurs structurées avant et après, lorsque disponibles |
detected_at | Horodatage pour la réponse opérationnelle et la création de rapports |
severity | Priorité commerciale telle que faible, moyenne, élevée ou critique |
diff_reference | Lien ou identifiant pour examiner l'historique complet des changements |
owner | Équipe ou système responsable de l'étape suivante |
Voici un exemple de charge utile simplifié :
{
"event_id": "chg_20260630_184522",
"source_url": "https://example-source.com/pricing",
"source_type": "pricing_page",
"change_type": "price_change",
"detected_at": "2026-06-30T18:45:22Z",
"old_value": "$99/month",
"new_value": "$89/month",
"severity": "high",
"owner": "revenue_ops"
}
Pas toutes les sources produiront chaque champ. Un changement de page de politiques peut avoir une différence de texte au lieu d'un prix ancien et nouveau. Un point de terminaison d'API peut inclure un chemin JSON modifié. Le point est de définir le contrat tôt afin que les systèmes en aval puissent traiter les événements de manière cohérente.
Configurez les règles de surveillance qui séparent le signal du bruit
Les pages Web changent constamment. Les bannières de cookies, les horodatages, les témoignages rotatifs, la personnalisation, les paramètres de suivi, les photos de stock, les publicités et les variantes de test A/B peuvent tous créer de faux positifs.
Le filtrage du bruit est ce qui rend la surveillance de site Web à API utilisable. Sans cela, les équipes cessent de faire confiance aux alertes et l'automatisation est désactivée.
Un bon filtrage inclut généralement plusieurs couches. Premièrement, surveillez la partie la plus pertinente de la page au lieu de l'ensemble du DOM lorsque cela est possible. Deuxièmement, normalisez les changements de formatage tels que les espaces, la capitalisation ou le formatage des devises lorsqu'ils ne sont pas significatifs. Troisièmement, appliquez des seuils afin que de minuscules éditions de copie ne déclenchent pas des flux de travail à haute priorité. Quatrièmement, débouncez les changements répétés afin qu'une page instable ne submerge pas votre API de réception.
Ceci est particulièrement important pour les flux de travail opérationnels. Une notification Slack peut être ignorée si elle est bruyante. Un événement d'API peut créer un ticket, mettre à jour un enregistrement, notifier un propriétaire de compte ou déclencher un processus d'approbation, donc les faux positifs ont un coût réel.
DiffHook est construit autour de ce type de surveillance pratique, y compris la détection de changements en temps réel, le suivi de pages, de flux et d'API, les alertes de changement de prix, le filtrage intelligent du bruit, les notifications Slack et électronique, les webhooks, les intégrations de flux de travail et l'historique complet des changements.
Acheminez les alertes et les événements d'API différemment
Une erreur courante consiste à envoyer chaque changement à chaque canal. Les humains ont besoin de contexte et de priorisation. Les systèmes ont besoin de données structurées et d'une livraison prévisible. Ceux-ci sont liés, mais ne sont pas les mêmes.
Utilisez des alertes humaines pour les décisions d'examen, telles que les changements de politiques, les mises à jour de libellés juridiques et les mouvements de concurrents à forte incidence. Utilisez des événements d'API ou des webhooks lorsque le changement doit entrer dans un flux de travail automatiquement, tel que la création d'un ticket, la mise à jour d'un enregistrement, la notification d'un propriétaire de compte ou le déclenchement d'un processus d'approbation.
Si vous décidez quand les alertes suffisent et quand vous avez besoin d'une livraison structurée, l'article de DiffHook sur quand vous avez besoin d'une API pour les sites Web, et non seulement des alertes couvre le point de décision en profondeur.
La règle pratique est simple : si le destinataire est une personne, optimisez pour la clarté. Si le destinataire est un système, optimisez pour le schéma, l'idempotence et la fiabilité.
Conception du point de terminaison de réception pour la fiabilité
Une fois que les changements sont livrés sous forme d'événements d'API, votre système de réception devient partie intégrante du flux de travail de surveillance. Traitez-le comme une infrastructure de production.
Votre point de terminaison doit accepter uniquement les charges utiles qu'il comprend, valider les champs requis, stocker l'événement avant de procéder à un traitement lourd et renvoyer une réponse de réussite uniquement après que l'événement ait été accepté en toute sécurité. Si le traitement en aval échoue, l'événement doit toujours être récupérable à partir de votre propre file d'attente ou base de données.
Construire pour ces modèles de fiabilité :
- Idempotence, afin que le même événement puisse être réessayé sans créer de tickets ou d'enregistrements en double
- Authentification, en utilisant les méthodes de sécurité disponibles dans vos outils de surveillance et de flux de travail
- Codes de réponse clairs, afin que les échecs de livraison puissent être réessayés ou examinés
- Journalisation, afin que chaque événement reçu puisse être tracé à une source et à un horodatage
- Schémas de version, afin que vous puissiez ajouter des champs sans casser les consommateurs
Décidez également de la manière dont les échecs sont gérés. Si le destinataire est hors ligne, le système de surveillance doit-il réessayer ? Un humain doit-il être notifié après des échecs répétés ? Les changements critiques devraient-ils également aller sur Slack ou par courriel en tant que sauvegarde ? Ces décisions doivent être prises avant le premier incident.
Testez avec des changements contrôlés avant de passer en production
N'attendez pas qu'un changement réel de prix de concurrent ou une mise à jour de politique se produise pour savoir si le flux de travail fonctionne. Exécutez des tests contrôlés avant que la configuration de surveillance ne devienne opérationnelle.
| Test | Ce que vous devez vérifier | Échec à surveiller |
|---|
| Changement de texte d'exemple | La bonne section est surveillée | Le bruit de page complète déclenche une alerte |
| Changement de prix d'exemple | Les valeurs anciennes et nouvelles sont extraites correctement | La devise, la remise ou le formatage est mal lu |
| Livraison en double | Le destinataire gère les réessais en toute sécurité | Des tickets ou des enregistrements en double sont créés |
| Changement à faible priorité | Le routage correspond à la priorité | Tout changement mineur devient urgent |
| Défaillance du point de terminaison | La gestion des échecs fonctionne | Les événements disparaissent sans examen |
| Examen d'audit | L'historique des changements est disponible | Les équipes ne peuvent pas prouver ce qui a changé |
Les tests doivent inclure à la fois les utilisateurs techniques et commerciaux. Les ingénieurs peuvent confirmer la livraison, la validation du schéma et le comportement de réessai. Les propriétaires commerciaux peuvent confirmer si l'événement contient suffisamment de contexte pour agir.
