Se uma página web importante mudar e ninguém notar até que um cliente, regulador, parceiro ou concorrente reaja, o sistema de monitoramento falhou. Os alertas tradicionais de sites ajudam, mas muitas equipes agora precisam de algo mais operacional: uma maneira de transformar as alterações web em eventos estruturados que possam fluir para ferramentas internas, filas, painéis e fluxos de trabalho.
Essa é a ideia central por trás da monitoração de site para API. Você monitora páginas, preços, políticas, feeds e APIs, e então entrega as alterações significativas como payloads legíveis por API em vez de confiar apenas em capturas de tela ou alertas de inbox.
Feito bem, isso dá às equipes de receita, conformidade, jurídico, produto e operações uma camada de sinal compartilhada. Feito mal, cria notificações barulhentas, scrapers frágeis e automação que ninguém confia. Este guia percorre uma configuração prática que mantém o fluxo de trabalho confiável desde o primeiro URL monitorado até o endpoint da API de recebimento.
O que significa monitoração de site para API
A monitoração de site para API não significa que todos os sites se tornam magicamente uma API estável e oficial. Se um fornecedor ou parceiro oferece uma API documentada que fornece os dados necessários, use-a. Ela geralmente será mais confiável, mais fácil de governar e mais clara do ponto de vista legal e operacional.
O caso de uso real é diferente: muitos sinais comerciais críticos ainda vivem em páginas web públicas, páginas de produtos, páginas de preços, documentação, listagens de mercado, páginas de política, feeds RSS, endpoints JSON, feeds XML e páginas semi-estruturadas que nunca foram projetadas para os sistemas. A monitoração de site para API transforma as alterações nesses recursos em eventos estruturados.
| Estilo de monitoramento | Melhor para | Saída | Limitação |
|---|
| Alertas apenas humanos | Revisão de baixo volume e decisões manuais | E-mail ou mensagem do Slack | Difícil de automatizar e medir |
| Monitoramento de alterações visuais | Layout, cópia, capturas de tela e alterações de política | Visão de diferença ou instantâneo | Pode ser barulhento sem filtro |
| Extração estruturada | Preços, disponibilidade, termos, campos, tabelas | Valores normalizados | Requer seletores claros ou regras de parsing |
| Fluxo de trabalho de site para API | Automação operacional e atualizações de sistema | Webhook ou payload de API | Precisa de esquema, roteamento e governança |
Uma configuração boa combina essas abordagens. Algumas alterações devem ir para os humanos para revisão. Outras devem criar tickets, atualizar registros internos, acionar um fluxo de receita, notificar um serviço downstream imediatamente.
Comece com a decisão, não com o URL
A maneira mais rápida de criar uma configuração de monitoramento frágil é começar com uma lista gigante de URLs. Um ponto de partida melhor é a decisão que a equipe precisa tomar quando algo muda.
Pergunte: se essa página mudar, quem age, como rápido e que informações eles precisam?
Por exemplo, uma equipe de receita pode monitorar páginas de preços de concorrentes porque uma queda de preço deve acionar uma atualização de habilitação de vendas. Uma equipe de conformidade pode monitorar páginas de política de fornecedores porque novas palavras podem afetar compromissos de clientes. Uma equipe de operações de produto pode monitorar documentação de API porque um campo obsoleto pode quebrar uma integração.
Uma monitoração de site para API forte começa com um sinal comercial, como:
- Um concorrente muda um preço público, limite de plano ou termo de embalagem
- Um fornecedor atualiza uma política de privacidade, SLA, política de uso aceitável ou página de segurança
- Uma listagem de mercado adiciona, remove ou muda um produto
- Um feed publica um novo registro que deve entrar em um fluxo de trabalho interno
- Uma resposta de API muda de uma maneira que afeta sistemas downstream
Uma vez que a decisão esteja clara, a configuração técnica se torna mais fácil. Você sabe o que extrair, como often verificar, quais alterações são ruído e para onde o evento resultante deve ir.
Construa um mapa de fontes em páginas, feeds e APIs
A maioria das equipes descobre que seu cenário de monitoramento é mais amplo do que o esperado. Um processo comercial único pode depender de uma página de preços, uma página de documentação, uma página de status, um endpoint JSON e um feed de parceiro.
Crie um mapa de fontes antes de configurar alertas. No mínimo, capture o URL, proprietário, tipo de fonte, razão comercial, frequência de alteração esperada e tempo de resposta necessário. Isso evita que o monitoramento se torne uma coleção de verificações desconectadas.
| Tipo de fonte | Sinal de exemplo | Abordagem de monitoramento recomendada | Destino típico |
|---|
| Página de preços | Alterações de preços de planos ou descontos | Extração de preços mais diferença de página | Canal de receita ou fluxo de trabalho do CRM |
| Página de política | Alterações de palavras legais ou datas de vigência | Diferença de texto com filtro de ruído | Fila de revisão de conformidade |
| Página de produto | Alterações de disponibilidade, recursos ou especificações | Rastreamento de campos estruturados | Alerta de operações ou vendas |
| Feed RSS ou XML | Item novo ou removido | Monitoramento de feed | Fluxo de trabalho de conteúdo ou catálogo |
| Endpoint de API | Alteração de campo, status ou resposta | Monitoramento de resposta de API | Fluxo de trabalho de engenharia ou incidente |
Se você precisar de um quadro mais amplo para organizar fontes, o guia da DiffHook sobre como capturar alterações de site em páginas, feeds e APIs é um acompanhante útil para esse processo de configuração.
A chave é evitar tratar todas as fontes igualmente. Uma página de preços de alto impacto pode precisar de detecção rápida e roteamento automatizado. Um feed de blog de baixo risco pode precisar apenas de um resumo diário. Uma página de política pode precisar de histórico de alterações completo e revisão humana antes de qualquer ação ser tomada.
Defina o esquema de evento antes de monitorar
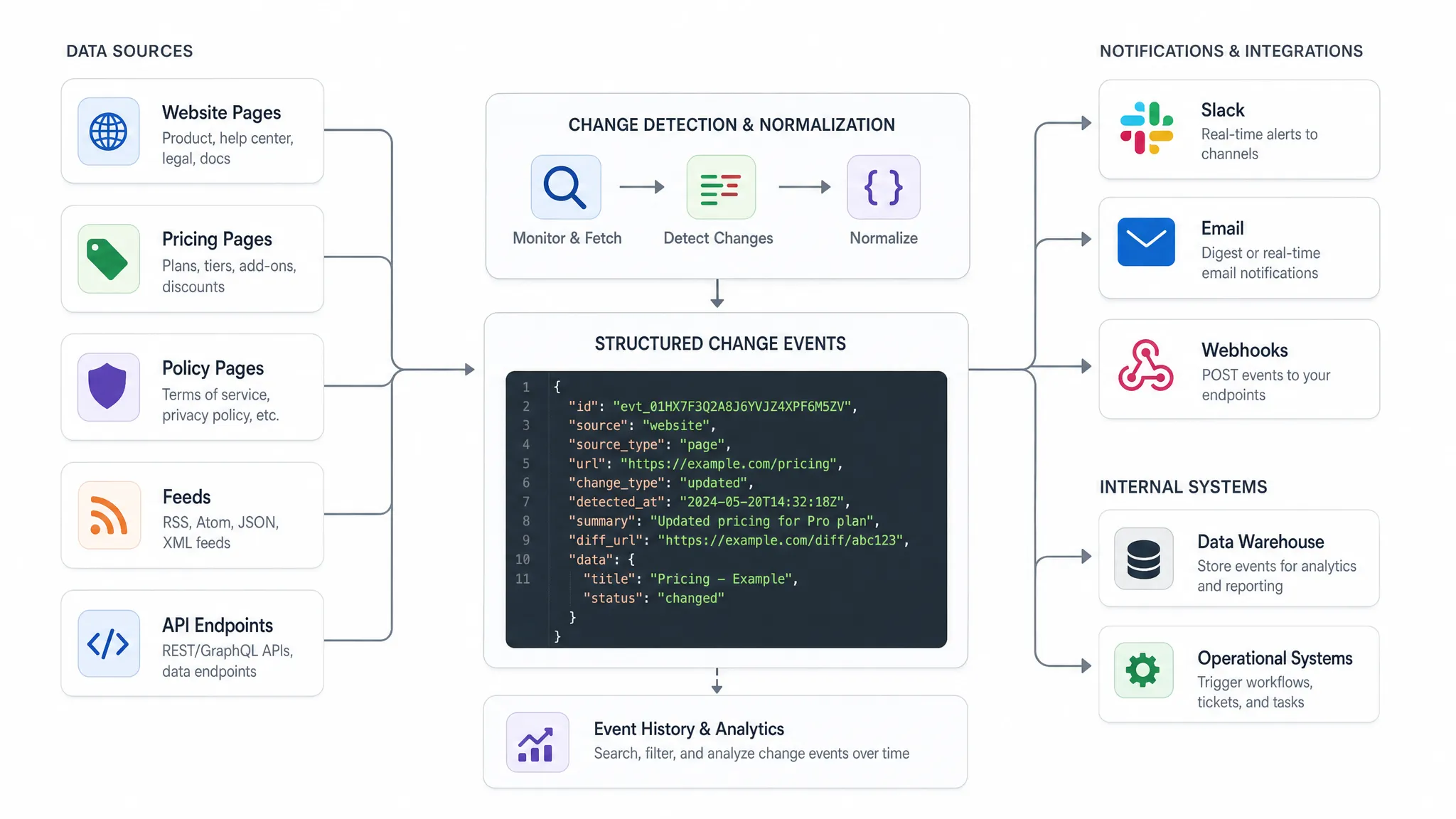
A API de recebimento não deve receber uma mensagem vaga que diga "alguma coisa mudou". Ela deve receber um evento estruturado com contexto suficiente para agir.
Um esquema de evento prático geralmente responde a cinco perguntas: o que mudou, onde mudou, quando foi detectado, quão importante é e o que deve acontecer em seguida.
| Campo | Propósito |
|---|
event_id | Identificador único para deduplicação e auditoria |
source_url | A página, feed ou endpoint monitorado |
source_type | Página, feed, API, preço, política ou categoria personalizada |
change_type | Alteração de preço, alteração de texto, item adicionado, item removido, resposta alterada |
old_value e new_value | Valores estruturados antes e depois, quando disponíveis |
detected_at | Carimbo de data/hora para resposta operacional e relatórios |
severity | Prioridade comercial, como baixa, média, alta ou crítica |
diff_reference | Link ou identificador para revisar o histórico de alterações completo |
owner | Equipe ou sistema responsável pelo próximo passo |
Aqui está um exemplo de payload simplificado:
{
"event_id": "chg_20260630_184522",
"source_url": "https://example-source.com/pricing",
"source_type": "pricing_page",
"change_type": "price_change",
"detected_at": "2026-06-30T18:45:22Z",
"old_value": "$99/month",
"new_value": "$89/month",
"severity": "high",
"owner": "revenue_ops"
}
Não todas as fontes produzirão todos os campos. Uma alteração de página de política pode ter uma diferença de texto em vez de um preço antigo e novo. Um endpoint de API pode incluir um caminho JSON alterado. O ponto é definir o contrato cedo, para que os sistemas downstream possam processar eventos consistentemente.
Configure regras de monitoramento que separam sinal de ruído
Páginas web mudam constantemente. Banners de cookies, carimbos de data/hora, testemunhos rotativos, personalização, parâmetros de rastreamento, fotos de estoque, anúncios e variantes de teste A/B podem criar falsos positivos.
O filtro de ruído é o que torna a monitoração de site para API útil. Sem ele, as equipes param de confiar nos alertas e a automação é desativada.
Um bom filtro geralmente inclui várias camadas. Primeiro, monitore a parte mais relevante da página em vez de todo o DOM, quando possível. Segundo, normalize alterações de formatação, como espaçamento, capitalização ou formatação de moeda, quando não são significativas. Terceiro, aplique limiares para que pequenas edições de cópia não acionem fluxos de trabalho de alta severidade. Quarto, debote alterações repetidas para que uma página instável não inunde a API de recebimento.
Isso é especialmente importante para fluxos de trabalho operacionais. Uma notificação do Slack pode ser ignorada se for barulhenta. Um evento de API pode criar um ticket, atualizar um registro ou acionar um processo downstream, então falsos positivos têm um custo real.
A DiffHook é construída em torno desse tipo de monitoramento prático, incluindo detecção de alterações em tempo real, rastreamento de páginas, feeds e APIs, alertas de alterações de preços, filtro de ruído inteligente, notificações do Slack e e-mail, webhooks, integrações de fluxo de trabalho e histórico de alterações completo.
Roteie alertas e eventos de API de forma diferente
Um erro comum é enviar todas as alterações para todos os canais. Humanos precisam de contexto e priorização. Sistemas precisam de dados estruturados e entrega previsível. Essas são coisas relacionadas, mas não as mesmas.
Use alertas humanos para decisões que exigem revisão, como alterações de política, atualizações de palavras legais e movimentos de concorrentes de alto impacto. Use eventos de API ou webhooks quando a alteração deve entrar em um fluxo de trabalho automaticamente, como criar um ticket, atualizar um registro, notificar um proprietário de conta ou iniciar um processo de aprovação.
Se você está decidindo quando os alertas são suficientes e quando você precisa de entrega estruturada, o artigo da DiffHook sobre quando você precisa de uma API para sites, não apenas alertas cobre o ponto de decisão em mais detalhes.
A regra prática é simples: se o destinatário for uma pessoa, otimize para clareza. Se o destinatário for um sistema, otimize para esquema, idempotência e confiabilidade.
Projete o endpoint de recebimento para confiabilidade
Uma vez que as alterações sejam entregues como eventos de API, o sistema de recebimento se torna parte do fluxo de trabalho de monitoramento. Trate-o como infraestrutura de produção.
O endpoint deve aceitar apenas os payloads que entende, validar campos necessários, armazenar o evento antes de fazer processamento pesado e retornar uma resposta de sucesso apenas após o evento ser aceito com segurança. Se o processamento downstream falhar, o evento ainda deve ser recuperável da própria fila ou banco de dados.
Construa para esses padrões de confiabilidade:
- Idempotência, para que o mesmo evento possa ser repetido sem criar tickets ou registros duplicados
- Autenticação, usando os métodos de segurança disponíveis nas ferramentas de monitoramento e fluxo de trabalho
- Códigos de resposta claros, para que falhas de entrega possam ser repetidas ou investigadas
- Registro, para que cada evento recebido possa ser rastreado até uma fonte e carimbo de data/hora
- Esquemas de versão, para que você possa adicionar campos sem quebrar consumidores
Também decida como as falhas são tratadas. Se o receptor estiver inativo, o plataforma de monitoramento deve repetir? Um humano deve ser notificado após falhas repetidas? Alterações críticas também devem ir para o Slack ou e-mail como fallback? Essas decisões devem ser tomadas antes do primeiro incidente.
Teste com alterações controladas antes de ir ao vivo
Não espere uma alteração real de preço de concorrente ou atualização de política para descobrir se o fluxo de trabalho funciona. Execute testes controlados antes de a configuração de monitoramento se tornar operacional.
| Teste | O que verificar | Falha para assistir |
|---|
| Alteração de texto de exemplo | A seção certa é monitorada | Ruído de página completa dispara um alerta |
| Alteração de preço de exemplo | Valores antigos e novos são extraídos corretamente | Moeda, desconto ou formatação é mal lido |
| Entrega duplicada | Receptor lida com repetições com segurança | Tickets ou registros duplicados são criados |
| Alteração de baixa severidade | Roteamento corresponde à prioridade | Todas as alterações menores se tornam urgentes |
| Falha de endpoint | Tratamento de falha funciona | Eventos desaparecem sem revisão |
| Revisão de auditoria | Histórico de alterações está disponível | Equipes não podem provar o que mudou |
Os testes devem incluir tanto usuários técnicos quanto comerciais. Engenheiros podem confirmar entrega, validação de esquema e comportamento de repetição. Proprietários de negócios podem confirmar se o evento contém enough contexto para agir.
