Wenn eine wichtige Webseite ändert und niemand es bemerkt, bis ein Kunde, Regulator, Partner oder Wettbewerber reagiert, hat das Überwachungssystem versagt. Traditionelle Website-Alarme helfen, aber viele Teams benötigen jetzt etwas Operatives: Eine Möglichkeit, Webseitenänderungen in strukturierte Ereignisse umzuwandeln, die in interne Tools, Warteschlangen, Dashboards und Workflows fließen können.
Das ist die Kernidee hinter Website-zu-API-Überwachung. Sie überwachen Seiten, Preise, Richtlinien, Feeds und APIs und liefern die bedeutungsvollen Änderungen als API-lesbare Payloads, anstatt sich nur auf Screenshots oder Inbox-Alarme zu verlassen.
Wenn es gut gemacht wird, gibt dies den Teams für Umsatz, Compliance, Recht, Produkt und Betrieb eine gemeinsame SignalEbene. Wenn es schlecht gemacht wird, entstehen lautstarke Benachrichtigungen, fragile Scraper und Automatisierungen, die niemand vertraut. Dieser Leitfaden führt durch eine praktische Einrichtung, die den Workflow von der ersten überwachten URL bis zum Empfangs-API-Endpunkt zuverlässig hält.
Was Website-zu-API-Überwachung bedeutet
Website-zu-API-Überwachung bedeutet nicht, dass jede Webseite magisch zu einer stabilen, offiziellen API wird. Wenn ein Lieferant oder Partner eine dokumentierte API anbietet, die Ihnen die benötigten Daten liefert, sollten Sie sie verwenden. Sie wird in der Regel zuverlässiger, einfacher zu regeln und klarer von einem rechtlichen und betrieblichen Standpunkt aus sein.
Der eigentliche Anwendungsfall ist anders: Viele kritische GeschäftsSignale leben noch auf öffentlichen Webseiten, Produktseiten, Preislisten, Dokumentationen, Marktplatzlisten, Richtlinienseiten, RSS-Feeds, JSON-Endpunkten, XML-Feeds und halbstrukturierten Seiten, die nie für Ihre Systeme konzipiert wurden. Website-zu-API-Überwachung wandelt Änderungen in diesen Quellen in strukturierte Ereignisse um.
| Überwachungsstil | Bestens für | Ausgabe | Einschränkung |
|---|
| Nur menschliche Alarme | Niedrigvolumen-Überprüfung und manuelle Entscheidungen | E-Mail oder Slack-Nachricht | Schwierig zu automatisieren und zu messen |
| Visuelle Änderungsüberwachung | Layout, Kopie, Screenshots und Richtlinienänderungen | Diff-Ansicht oder Snapshot | Kann ohne Filterung lautstark sein |
| Strukturierte Extraktion | Preise, Verfügbarkeit, Bedingungen, Felder, Tabellen | Normalisierte Werte | Benötigt klare Selektoren oder Parsing-Regeln |
| Website-zu-API-Workflow | Operative Automatisierung und Systemaktualisierungen | Webhook oder API-Payload | Benötigt Schema, Routing und Governance |
Eine gute Einrichtung kombiniert diese Ansätze. Einige Änderungen sollten an Menschen für die Überprüfung gehen. Andere sollten Tickets erstellen, interne Aufzeichnungen aktualisieren, einen Umsatz-Workflow auslösen oder einen nachgelagerten Dienst sofort benachrichtigen.
Beginnen Sie mit der Entscheidung, nicht der URL
Der schnellste Weg, um eine zerbrechliche Überwachungseinrichtung zu erstellen, ist, mit einer großen Liste von URLs zu beginnen. Ein besserer Ausgangspunkt ist die Entscheidung, die Ihr Team treffen muss, wenn sich etwas ändert.
Fragen Sie: Wenn sich diese Seite ändert, wer handelt, wie schnell und welche Informationen benötigt er?
Zum Beispiel kann ein Umsatzteam die Preislisten der Wettbewerber überwachen, weil ein Preisrückgang einen Vertriebsaktualisierungsprozess auslösen sollte. Ein Compliance-Team kann die Richtlinienseiten der Lieferanten überwachen, weil neue Formulierungen Kundenverpflichtungen beeinflussen könnten. Ein Produktionsbetriebsteam kann die API-Dokumentation überwachen, weil ein veralteter Feld ein Integrationssystem brechen könnte.
Starke Website-zu-API-Überwachung beginnt mit einem GeschäftsSignal wie:
- Ein Wettbewerber ändert einen öffentlichen Preis, eine Planbegrenzung oder eine Verpackungsklausel
- Ein Lieferant aktualisiert eine Datenschutzrichtlinie, eine SLA, eine akzeptable Nutzungspolitik oder eine Sicherheitsseite
- Eine Marktplatzliste fügt ein Produkt hinzu, entfernt es oder ändert es
- Ein Feed veröffentlicht einen neuen Datensatz, der in einen internen Workflow eingegeben werden sollte
- Eine API-Antwort ändert sich auf eine Weise, die nachgelagerte Systeme beeinflusst
Sobald die Entscheidung klar ist, wird die technische Einrichtung einfacher. Sie wissen, was zu extrahieren ist, wie oft zu überprüfen ist, welche Änderungen Rauschen sind und wohin das resultierende Ereignis gehen sollte.
Erstellen Sie eine Quellenkarte über Seiten, Feeds und APIs
Die meisten Teams entdecken, dass ihre Überwachungslandschaft breiter ist als erwartet. Ein einzelner Geschäftsprozess kann von einer Preisliste, einer Dokumentationsseite, einer Statusseite, einem JSON-Endpunkt und einem Partner-Feed abhängen.
Erstellen Sie eine Quellenkarte, bevor Sie Alarme konfigurieren. Mindestens erfassen Sie die URL, den Besitzer, den Quellentyp, den Geschäftsgrund, die erwartete Änderungshäufigkeit und die erforderliche Reaktionszeit. Dies verhindert, dass die Überwachung zu einer Sammlung von nicht verbundenen Überprüfungen wird.
| Quellentyp | Beispiel-Signal | Empfohlener Überwachungsansatz | Typischer Zielort |
|---|
| Preisliste | Planpreis- oder Rabattänderungen | Preisextraktion plus Seitendiff | Umsatzkanal oder CRM-Workflow |
| Richtlinienseite | Rechtliche Formulierungen oder Änderungen des Inkrafttretens | Textdiff mit Rauschfilterung | Compliance-Überprüfungswarteschlange |
| Produktseite | Verfügbarkeit, Funktionen oder Spezifikationen | Strukturierte Feldverfolgung | Betriebs- oder Vertriebsalarm |
| RSS- oder XML-Feed | Neues Element oder entferntes Element | Feed-Überwachung | Inhalt- oder Katalog-Workflow |
| API-Endpunkt | Feld-, Status- oder Antwortänderung | API-Antworten-Überwachung | Engineering- oder Incident-Workflow |
Wenn Sie ein breiteres Framework für die Organisation von Quellen benötigen, ist DiffHooks Leitfaden zu Änderungen auf Seiten, Feeds und APIs ein nützlicher Begleiter bei diesem Einrichtungsprozess.
Der Schlüssel ist, nicht alle Quellen gleich zu behandeln. Eine hochwirkungsvolle Preisliste kann eine schnelle Erkennung und automatisierte Weiterleitung benötigen. Ein niedriges Risiko-Blog-Feed kann nur eine tägliche Zusammenfassung benötigen. Eine Richtlinienseite kann eine vollständige Änderungshistorie und eine menschliche Überprüfung vor jeder Aktion benötigen.
Definieren Sie das Ereignisschema, bevor Sie überwachen
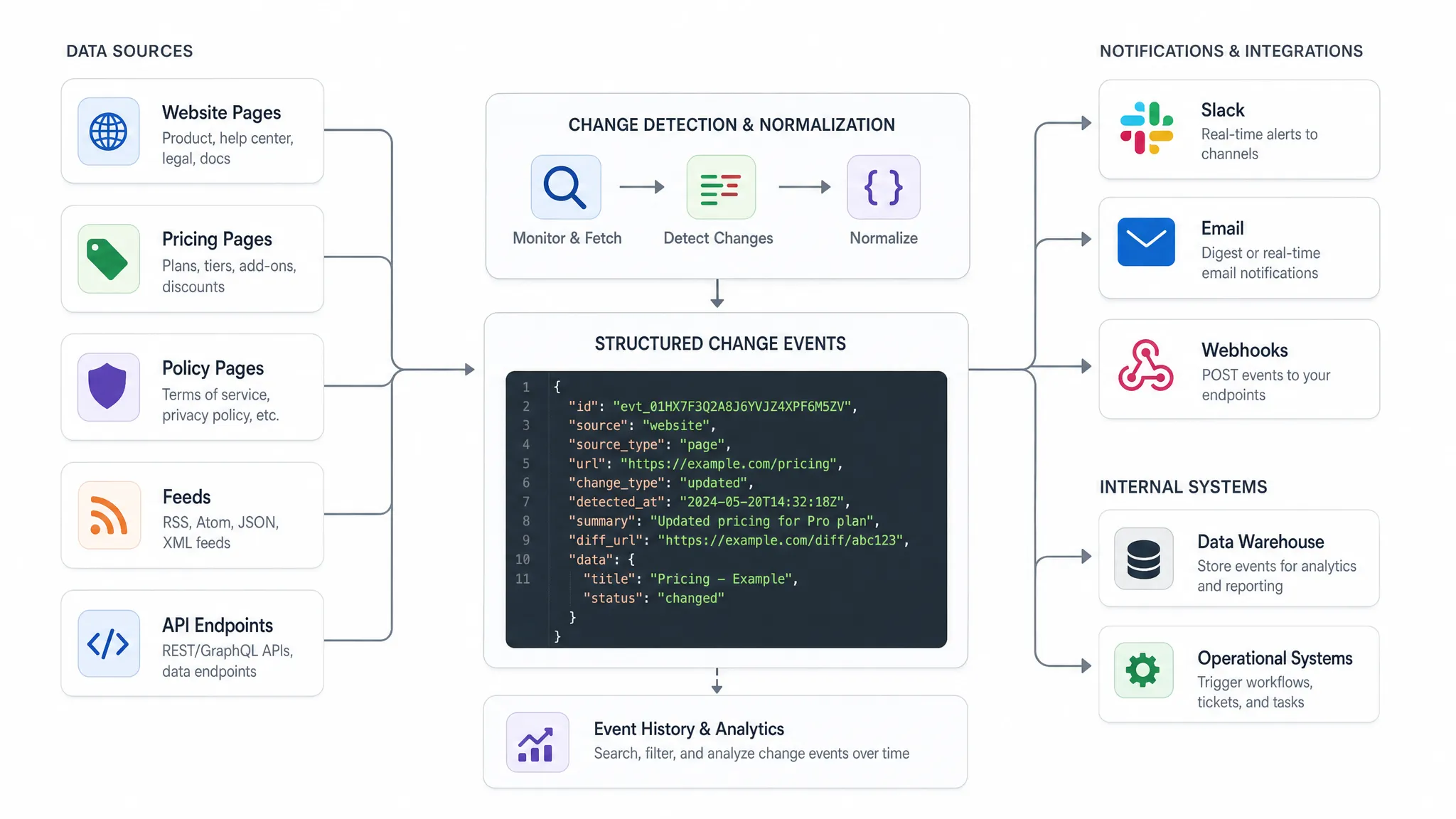
Der Empfangs-API sollte nicht eine vage Nachricht erhalten, die sagt: „Etwas hat sich geändert.“ Sie sollte ein strukturiertes Ereignis mit genügend Kontext erhalten, um zu handeln.
Ein praktisches Ereignisschema beantwortet in der Regel fünf Fragen: Was hat sich geändert, wo hat es sich geändert, wann wurde es erkannt, wie wichtig ist es und was sollte als Nächstes geschehen.
| Feld | Zweck |
|---|
event_id | Eindeutiger Identifikator für Deduplizierung und Prüfbarkeit |
source_url | Die überwachte Seite, der Feed oder der Endpunkt |
source_type | Seite, Feed, API, Preis, Richtlinie oder benutzerdefinierte Kategorie |
change_type | Preisänderung, Textänderung, Element hinzugefügt, Element entfernt, Antwort geändert |
old_value und new_value | Strukturierte Werte vor und nach der Änderung, wenn verfügbar |
detected_at | Timestamp für operative Reaktion und Berichterstellung |
severity | Geschäftliche Priorität wie niedrig, mittel, hoch oder kritisch |
diff_reference | Link oder Identifikator für die Überprüfung der vollständigen Änderungshistorie |
owner | Team oder System, das für den nächsten Schritt verantwortlich ist |
Hier ist ein vereinfachtes Payload-Beispiel:
{
"event_id": "chg_20260630_184522",
"source_url": "https://example-source.com/pricing",
"source_type": "pricing_page",
"change_type": "price_change",
"detected_at": "2026-06-30T18:45:22Z",
"old_value": "$99/month",
"new_value": "$89/month",
"severity": "high",
"owner": "revenue_ops"
}
Nicht jede Quelle wird jedes Feld produzieren. Eine Richtlinienänderung kann einen Textdiff anstelle eines alten und neuen Preises haben. Ein API-Endpunkt kann einen geänderten JSON-Pfad enthalten. Der Punkt ist, das Vertragswerk frühzeitig zu definieren, damit nachgelagerte Systeme Ereignisse konsistent verarbeiten können.
Konfigurieren Sie Überwachungsregeln, die Signal von Rauschen trennen
Webseiten ändern sich ständig. Cookie-Banner, Timestamps, rotierende Testimonials, Personalisierung, Tracking-Parameter, Aktienfotos, Anzeigen und A/B-Test-Varianten können alle falsche Positives erzeugen.
Rauschfilterung ist das, was Website-zu-API-Überwachung nutzbar macht. Ohne sie hören Teams auf, Alarme und Automatisierungen zu vertrauen.
Gute Filterung umfasst in der Regel mehrere Schichten. Zuerst überwachen Sie den relevantesten Teil der Seite anstelle des gesamten DOM, wenn möglich. Zweitens normalisieren Sie Formatierungsänderungen wie Leerzeichen, Groß- und Kleinschreibung oder Währungsformatierung, wenn sie nicht bedeutungsvoll sind. Drittens wenden Sie Schwellenwerte an, damit kleine Kopieränderungen keine hochpriorisierten Workflows auslösen. Viertens debouncen Sie wiederholte Änderungen, damit eine unstabile Seite Ihre Empfangs-API nicht überflutet.
Dies ist besonders wichtig für operative Workflows. Eine Slack-Benachrichtigung kann ignoriert werden, wenn sie lautstark ist. Ein API-Ereignis kann ein Ticket erstellen, einen Datensatz aktualisieren oder einen nachgelagerten Prozess auslösen, sodass falsche Positives einen realen Kostenfaktor hat.
DiffHook ist um diese Art von praktischer Überwachung herum aufgebaut, einschließlich Echtzeit-Änderungserkennung, Seiten-, Feed- und API-Verfolgung, Preisänderungs-Alarme, intelligenter Rauschfilterung, Slack- und E-Mail-Benachrichtigungen, Webhooks, Workflow-Integrationen und vollständiger Änderungshistorie.
Leiten Sie Alarme und API-Ereignisse unterschiedlich
Ein häufiger Fehler ist, jede Änderung an jeden Kanal zu senden. Menschen benötigen Kontext und Priorisierung. Systeme benötigen strukturierte Daten und vorhersehbare Lieferung. Diese sind verwandt, aber nicht dasselbe.
Verwenden Sie menschliche Alarme für überprüfungsintensive Entscheidungen, wie Richtlinienänderungen, rechtliche Formulierungsaktualisierungen und hochwirkungsvolle Wettbewerbsbewegungen. Verwenden Sie API-Ereignisse oder Webhooks, wenn die Änderung automatisch in einen Workflow eingegeben werden sollte, wie z. B. das Erstellen eines Tickets, das Aktualisieren einer Datenbank, das Benachrichtigen eines Kontoinhabers oder das Starten eines Genehmigungsprozesses.
Wenn Sie entscheiden, wann Alarme ausreichen und wann Sie strukturierte Lieferung benötigen, deckt DiffHooks Artikel zu wann Sie eine API für Webseiten benötigen, nicht nur Alarme den Entscheidungspunkt ausführlicher ab.
Die praktische Regel ist einfach: Wenn der Empfänger eine Person ist, optimieren Sie für Klarheit. Wenn der Empfänger ein System ist, optimieren Sie für Schema, Idempotenz und Zuverlässigkeit.
Entwerfen Sie den Empfangs-Endpunkt für Zuverlässigkeit
Sobald Änderungen als API-Ereignisse geliefert werden, wird Ihr Empfangssystem Teil des Überwachungs-Workflows. Behandeln Sie es wie Produktionsinfrastruktur.
Ihr Endpunkt sollte nur die Payloads akzeptieren, die er versteht, erforderliche Felder validieren, das Ereignis vor der Ausführung von Heavy-Processing speichern und nur nachdem das Ereignis sicher akzeptiert wurde, eine Erfolgsantwort zurückgeben. Wenn die nachgelagerte Verarbeitung fehlschlägt, sollte das Ereignis immer noch aus Ihrer eigenen Warteschlange oder Datenbank wiederhergestellt werden.
Bauen Sie für diese Zuverlässigkeitsmuster:
- Idempotenz, damit das gleiche Ereignis ohne Erstellung von doppelten Tickets oder Aufzeichnungen wiederholt werden kann
- Authentifizierung, unter Verwendung der Sicherheitsmethoden, die in Ihren Überwachungs- und Workflow-Tools verfügbar sind
- Klare Antwortcodes, damit Lieferfehler wiederholt oder untersucht werden können
- Protokollierung, damit jedes empfangene Ereignis einer Quelle und einem Timestamp zugeordnet werden kann
- Versionierte Schemata, damit Sie Felder hinzufügen können, ohne Verbraucher zu brechen
Entscheiden Sie auch, wie Fehler gehandhabt werden. Wenn der Empfänger down ist, sollte die Überwachungsplattform wiederholen? Sollte ein Mensch nach wiederholten Fehlern benachrichtigt werden? Sollten kritische Änderungen auch an Slack oder E-Mail als Fallback gesendet werden? Diese Entscheidungen sollten vor dem ersten Zwischenfall getroffen werden.
Testen Sie mit kontrollierten Änderungen, bevor Sie live gehen
Warten Sie nicht auf eine reale Preisänderung oder Richtlinienaktualisierung eines Wettbewerbers, um zu sehen, ob der Workflow funktioniert. Führen Sie kontrollierte Tests durch, bevor die Überwachungseinrichtung operativ wird.
| Test | Was zu überprüfen ist | Ausfall zu beobachten |
|---|
| Beispiel-Textänderung | Der richtige Abschnitt wird überwacht | Vollseiten-Rauschen löst einen Alarm aus |
| Beispiel-Preisänderung | Alte und neue Werte werden korrekt extrahiert | Währung, Rabatt oder Formatierung wird falsch gelesen |
| Doppelte Lieferung | Der Empfänger behandelt Wiederholungen sicher | Doppelte Tickets oder Aufzeichnungen werden erstellt |
| Niedrigprioritäts-Änderung | Routing entspricht Priorität | Jede kleine Änderung wird zu einer dringenden Angelegenheit |
| Endpunkt-Ausfall | Fehlerbehandlung funktioniert | Ereignisse verschwinden ohne Überprüfung |
| Prüf-Überprüfung | Änderungshistorie ist verfügbar | Teams können nicht beweisen, was sich geändert hat |
Die Tests sollten sowohl technische als auch geschäftliche Benutzer umfassen. Ingenieure können Lieferung, Schemavalidierung und Wiederholungsverhalten bestätigen. Geschäftsinhaber können bestätigen, ob das Ereignis den erforderlichen Kontext enthält.
