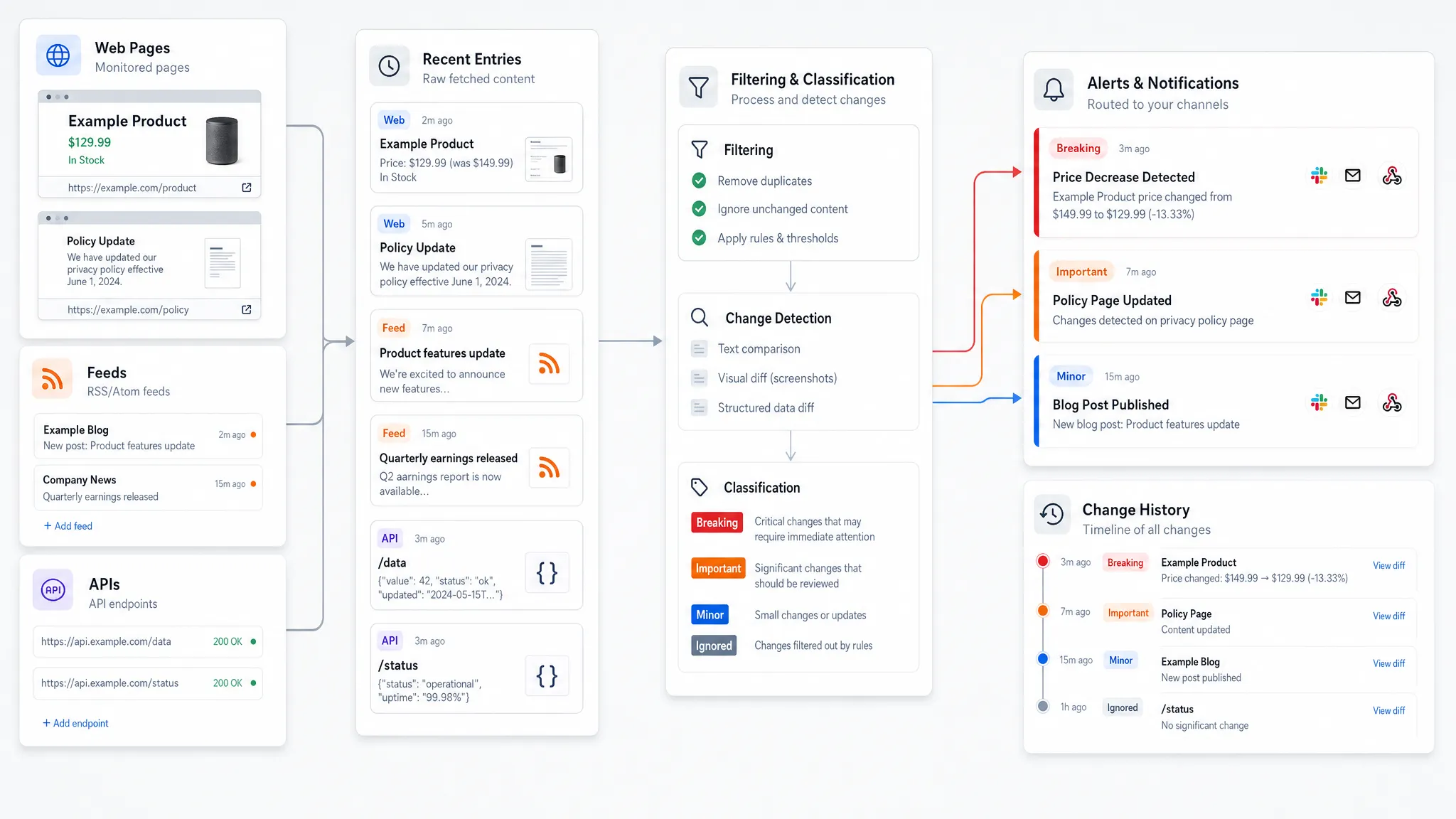
In 2026, the web is not just a marketing channel. It is an operational surface area. Competitor pricing changes, vendor policy updates, product page edits, API response shifts, broken feeds, and compliance language changes can all affect revenue, risk, and customer experience within minutes.
That is why catching change fast is no longer a nice-to-have. It is a requirement for teams that depend on external web pages, marketplace listings, partner portals, public policies, structured feeds, and APIs. But speed is often misunderstood. A modern web system does not simply refresh pages more frequently. It combines monitoring coverage, filtering, alert routing, reliability, and auditability into one workflow.
If your team wants fewer surprises and faster decisions, here is what a modern web system needs to detect meaningful change quickly without flooding everyone with noise.
Fast change detection is a system problem, not a crawler problem
A basic crawler can fetch a page. A modern web system has to do much more. It needs to know what sources matter, how often to check them, which parts of the source are important, what changed, whether the change is meaningful, who should know, and how that alert should be recorded.
That lifecycle matters because the value of monitoring is not the detection itself. The value is the action that follows. If a competitor changes a core offer at 9:00 a.m. and your revenue team sees it at 4:00 p.m., you technically detected the change, but you did not catch it fast enough to respond well.
The best systems treat web change monitoring as a pipeline:
Source monitoring comes first, followed by comparison, noise filtering, alert delivery, workflow integration, and historical recordkeeping. If any step is weak, the entire process slows down.
What fast really means
Fast does not mean every page must be checked every second. That would be expensive, noisy, and unnecessary for many sources. Fast means the system can match monitoring urgency to business impact and deliver the right alert quickly when a meaningful change happens.
| Speed layer | What it measures | Why it matters |
|---|
| Detection latency | Time between the web change and the system noticing it | Determines how soon your team becomes aware |
| Processing latency | Time needed to compare, classify, and filter the change | Prevents raw diffs from becoming noise |
| Delivery latency | Time between confirmed change and notification | Ensures alerts reach Slack, email, or workflows quickly |
| Action latency | Time between alert and team response | Depends on context, ownership, and escalation rules |
Many teams focus only on detection latency. In practice, delivery and action latency are often the bigger problem. A change hidden in a crowded inbox is not meaningfully faster than a change found manually hours later.
Broad source coverage across pages, feeds, and APIs
Modern operations depend on more than standard web pages. A complete web system should be able to monitor multiple types of sources without forcing teams to build one-off scripts for each format.
For example, revenue teams may care about competitor landing pages, product availability, and pricing pages. Compliance teams may track public policy pages, terms of service, disclosures, and regulatory notices. Operations teams may depend on vendor status pages, feeds, partner documentation, or API responses.
A practical system should support unstructured and structured sources. That includes page monitoring for visible content, feed tracking for recurring updates, and API tracking for machine-readable changes. When these live in separate tools, teams lose context. When they live in one monitoring system, it becomes easier to connect a policy edit, a feed update, and an API change to the same operational risk.
Coverage also needs to be maintainable. Web pages change structure. Feeds may add or remove fields. APIs may introduce new keys. A system that breaks every time a source layout changes will eventually become another operational burden.
Smart noise filtering that protects attention
The fastest alert is not always the best alert. If a system notifies your team every time a timestamp, rotating banner, tracking parameter, ad unit, stock message, or footer year changes, people will stop trusting it.
Noise filtering is one of the most important parts of a modern web system because attention is finite. The goal is not to detect every byte-level difference. The goal is to identify the changes that matter to the business.
Useful filtering usually includes normalization and rules. Normalization helps the system ignore predictable, low-value changes, such as dynamic IDs or repeated layout shifts. Rules help teams define which sections, fields, or values should trigger alerts.
For pages, that might mean focusing on a pricing block, compliance paragraph, CTA, policy section, or availability message. For feeds, it might mean watching for new entries, removed items, or changes to specific fields. For APIs, it might mean tracking key values, schema shifts, response changes, or unexpected status changes.
A good monitoring setup should also allow thresholds. A one-cent price change may not require the same action as a 15 percent change. A minor wording update may not need the same escalation as a change to cancellation terms. Filtering should reflect how your business actually works.
Monitoring cadence should match business risk
Not every source deserves the same monitoring frequency. High-risk and high-value sources should be checked more frequently. Stable reference pages may only need periodic checks. Matching cadence to risk helps control cost, reduce noise, and keep attention on what matters most.
| Source type | Typical business risk | Cadence mindset | Likely owner |
|---|
| Pricing or offer pages | Revenue impact, margin pressure, competitive response | Frequent or real-time for critical pages | Revenue, ecommerce, growth |
| Policy and terms pages | Compliance exposure, customer obligations, legal review | Frequent enough to support review SLAs | Legal, compliance, risk |
| Feeds and APIs | Operational breakage, data quality issues, workflow failures | Frequent for business-critical integrations | Ops, engineering, data |
| Vendor or partner pages | Service disruption, process changes, dependency risk | Based on dependency criticality | Operations, procurement |
| Content and landing pages | Campaign accuracy, brand consistency, conversion issues | Based on campaign priority | Marketing, web, growth |
The key is to avoid one-size-fits-all monitoring. A page that affects checkout revenue may need near real-time alerts. A reference page that changes twice a year may not. A modern system should make it easy to define that difference.
Alert delivery must be built for how teams work
A change alert is only useful if it reaches the right person in the right place with enough context to act. This is where many monitoring setups fail. They detect changes, but they deliver them in a way that creates friction.
A modern web system should support multiple alert paths, including Slack, email, webhooks, and workflow integrations. Slack is useful for team visibility and quick discussion. Email is useful for durable notification and external stakeholders. Webhooks are useful when a change needs to trigger another system, such as a ticket, incident workflow, CRM update, or internal automation.
Context matters as much as channel. An effective alert should make it clear what changed, where it changed, when it changed, and why the recipient is receiving it. If the alert only says that a page changed, someone still has to investigate. If it includes a focused diff, source details, and historical context, the team can move faster.
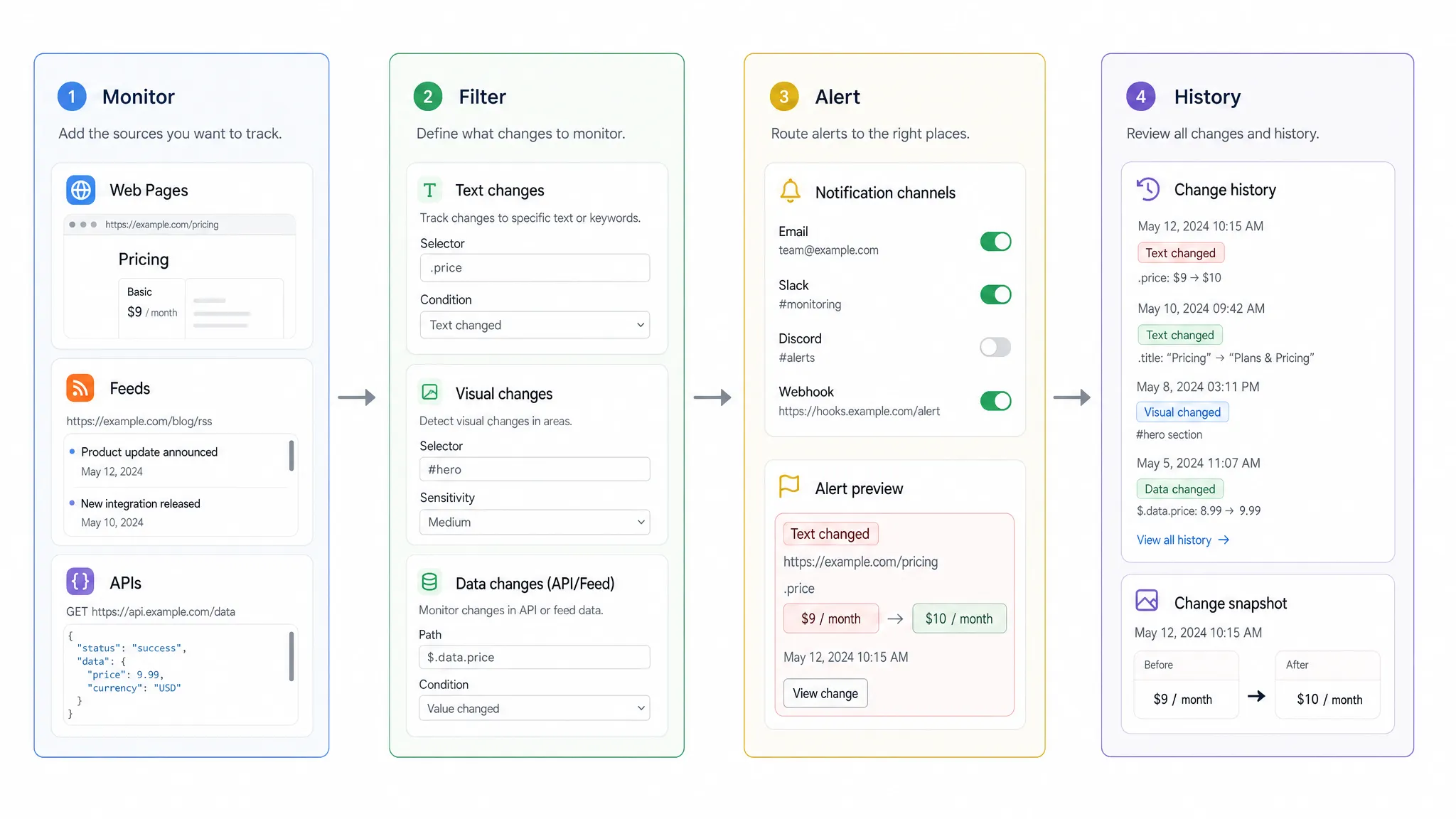
Full change history creates accountability
Fast alerts help teams respond now. Change history helps teams understand what happened later. Both are necessary.
A modern web system should preserve a reliable history of monitored changes. That history is useful for root-cause analysis, audits, vendor disputes, compliance reviews, and internal reporting. Without it, teams often end up relying on screenshots, forwarded emails, or memory.
Change history should answer practical questions. When did the change occur? What was the previous version? What changed in the new version? Which alert was sent? Was the change part of a recurring pattern? These questions become especially important when a web change affects contracts, regulatory exposure, pricing decisions, or customer commitments.
Audit trails also improve trust. If a compliance team needs to prove that it monitored a policy page and reviewed changes promptly, a documented trail is much stronger than an informal process.
Governance matters once monitoring becomes mission-critical
As monitoring expands, governance becomes essential. A small team can manage a few alerts informally. A larger organization needs access controls, ownership, and operational discipline.
Role-based access helps ensure that people can manage the sources and alerts relevant to their work without exposing everything to everyone. SSO can simplify access management for teams that already centralize identity. Hosting options may matter for organizations with regional data requirements or internal governance standards.
Governance also includes alert ownership. Every critical monitor should have a clear owner. If a policy page changes, who reviews it? If an API response changes, who investigates? If a competitor offer changes, who decides whether to respond? Monitoring without ownership creates awareness, but not action.
Integrations turn detection into response
A modern web system should not be a dead end. It should connect to the tools where teams already coordinate work.
For operations, that might mean creating tickets or triggering workflows. For engineering, it might mean sending structured payloads to internal systems. For revenue teams, it might mean notifying a pricing channel or updating a competitive intelligence workflow. For compliance, it might mean routing changes to a review queue.
Marketing teams can also benefit when external changes need a fast market response. For example, if a competitor launches a new offer or changes positioning, teams may route that insight into campaign workflows, and an AI-powered platform like Needle can help ecommerce brands generate and execute marketing assets more efficiently.
The principle is simple: the monitoring system should reduce the distance between detection and action. Webhooks and workflow integrations are often the bridge that makes that possible.
Build versus buy: what to consider
Some teams start with scripts. That can work for a small number of stable pages or APIs. But as monitoring becomes business-critical, custom scripts often accumulate hidden costs: maintenance, false positives, missed changes, brittle selectors, unclear alert routing, and no centralized history.
| Requirement | Custom scripts | Modern monitoring platform |
|---|
| Initial setup | Can be fast for simple sources | Usually faster for teams monitoring many source types |
| Maintenance | Requires ongoing engineering time | Platform handles much of the monitoring workflow |
| Noise filtering | Must be built and tuned manually | Built-in filtering and alert controls are expected |
| Alert delivery | Often limited to basic notifications | Slack, email, webhooks, and workflow routing are easier to manage |
| Change history | Must be stored and designed separately | Centralized history and audit trails are part of the system |
| Governance | Often missing unless built in | Role access, SSO, and team management can be supported |
Building can make sense when the use case is narrow, internal, and highly specialized. Buying usually makes more sense when multiple teams need reliable monitoring across pages, feeds, APIs, pricing, policies, and operational sources.
Evaluation checklist for a modern web system
When evaluating a change monitoring platform, focus on business outcomes rather than feature volume. The right system should help your team catch important changes quickly and respond with confidence.
Use these questions as a practical checklist:
- Can it monitor the source types your business depends on, including pages, feeds, and APIs?
- Does it support real-time or frequent monitoring for critical sources?
- Can it filter noisy changes so teams only see what matters?
- Does it deliver alerts through the channels your team actually uses?
- Can webhooks or integrations connect alerts to downstream workflows?
- Does it keep a full change history for investigation and audits?
- Does it support access control, SSO, and team governance needs?
- Can it support regional hosting requirements if your organization needs them?
- Is the system easy enough for non-engineering teams to manage safely?
The final question is especially important. A web system that only engineering can operate may not scale across revenue, compliance, and operations. The people closest to the business impact should be able to configure and act on relevant monitors without creating risk.
Where DiffHook fits
DiffHook is built for teams that need to know the moment important web changes happen. It monitors pages, prices, policies, feeds, and APIs, then alerts teams quickly when changes occur.
For organizations where web changes affect revenue, compliance, or operations, DiffHook brings the key pieces together: real-time change monitoring, smart noise filtering, Slack and email notifications, webhook and workflow integrations, full change history, audit trails, SSO and role access, and an EU hosting option.
That combination matters because speed alone is not enough. Teams also need confidence, context, and a reliable path from detection to response.
Frequently Asked Questions
What is a web system for change monitoring? A web system for change monitoring is a structured way to track external pages, feeds, APIs, and other online sources for meaningful changes. It combines source monitoring, comparison, filtering, alert delivery, integrations, and change history.
How fast should a monitoring system detect changes? It depends on business risk. Critical pricing, policy, feed, or API changes may need real-time or frequent monitoring. Lower-risk pages can often be checked less often. The goal is to match monitoring speed to the impact of missing the change.
How do modern systems reduce false alerts? They reduce false alerts by filtering noisy page elements, focusing on specific sections or fields, normalizing dynamic content, and allowing teams to define rules or thresholds for meaningful changes.
Should every team build its own web monitoring scripts? Not always. Scripts can work for narrow use cases, but they often become hard to maintain at scale. A dedicated monitoring platform is usually better when multiple teams need reliable alerts, integrations, governance, and audit history.
Which teams benefit most from fast web change alerts? Revenue, ecommerce, compliance, legal, operations, procurement, engineering, and growth teams can all benefit when external web changes affect decisions, obligations, workflows, or customer experience.
Catch web changes before they become business problems
The web changes constantly. The risk is not change itself, but finding out too late, missing the context, or sending the alert to the wrong place.
If your team depends on external pages, prices, policies, feeds, or APIs, a modern monitoring workflow can turn uncertainty into timely action. DiffHook helps teams detect important web changes fast, filter noise, route alerts, and preserve the history needed to respond with confidence.