Eine Website versagt selten in einem dramatischen Moment. Öfter ändert sich eine Preislinie ohne Vorwarnung, eine Checkout-Meldung verschwindet, eine Lieferantenrichtlinie ändert sich, ein Wettbewerber aktualisiert einen Plan oder ein Feed gibt einen neuen Wert zurück, der stillschweigend eine Annahme innerhalb Ihres Geschäfts bricht.
Wenn die erste Person, die es bemerkt, ein Kunde, Interessent, Partner oder Regulator ist, sind die Kosten bereits höher. Support-Tickets beginnen. Vertriebsteams erklären unvereinbare Preise. Compliance-Teams untersuchen nachträglich. Operations-Teams bemühen sich, zu verstehen, was geändert wurde und wann.
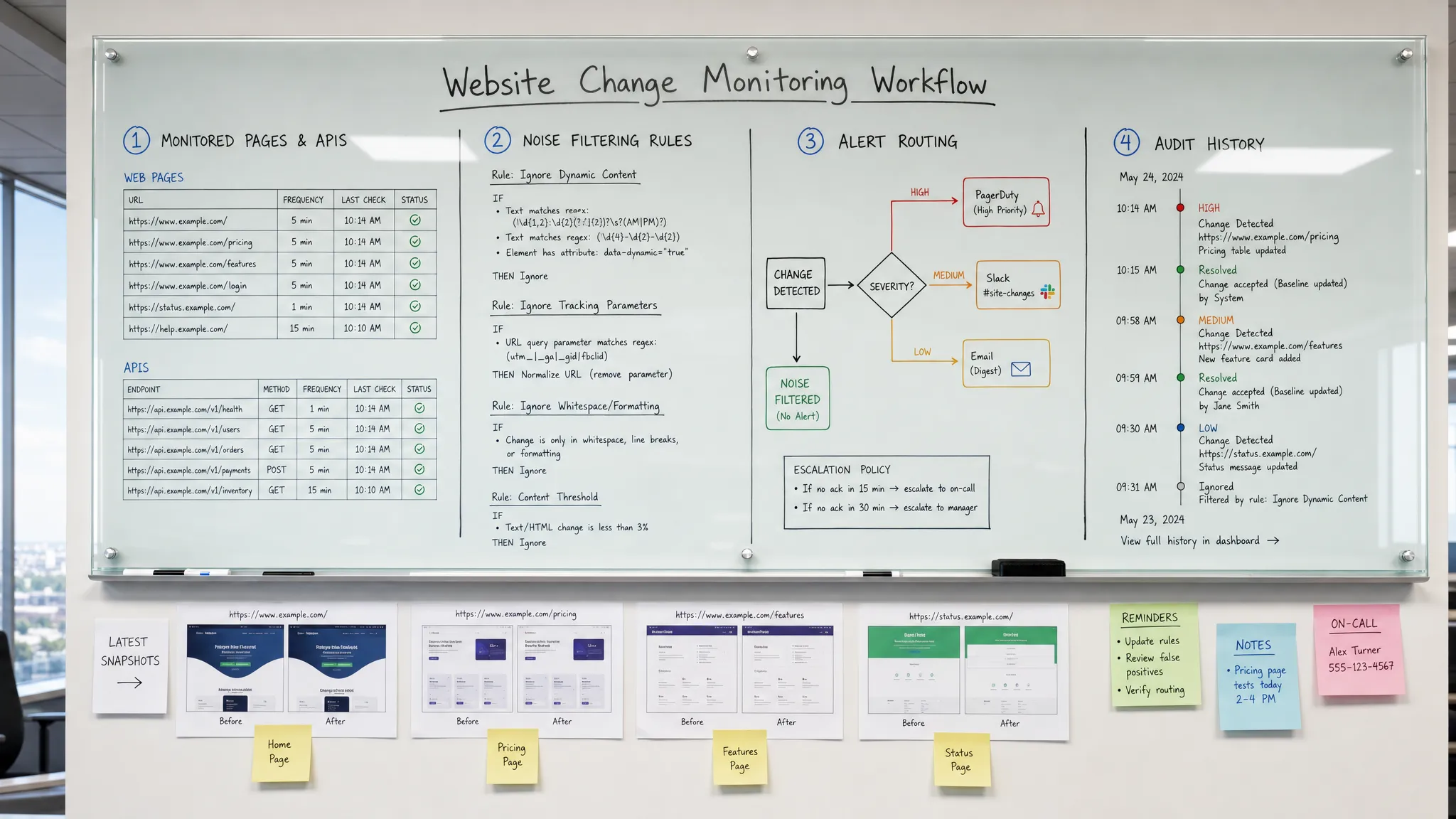
Um Website-Änderungen vor Kunden zu erkennen, benötigen Sie mehr als ein Tool, das sagt: „Diese Seite hat sich geändert.“ Sie benötigen einen Überwachungs-Workflow, der weiß, welche Änderungen wichtig sind, die richtigen Quellen mit der richtigen Geschwindigkeit überprüft, Rauschen filtert und handhabbare Alerts an die Personen sendet, die reagieren können.
Was „vor Kunden“ wirklich bedeutet
Das Erkennen von Änderungen frühzeitig ist nicht nur eine Frage der Geschwindigkeit. Geschwindigkeit ist wichtig, insbesondere für Preise, Richtlinien, Checkout, Verfügbarkeit und Partnerdaten, aber es ist nur ein Teil des Systems.
Ein praktischer Frühwarn-Workflow sollte zwei Lücken schließen:
- Die Erkennungslücke, also die Zeit zwischen einer Änderung und dem Wissen Ihres Teams darüber.
- Die Reaktionslücke, also die Zeit zwischen dem Wissen Ihres Teams und der richtigen Maßnahme durch den zuständigen Eigentümer.
Viele Teams konzentrieren sich nur auf die erste Lücke. Sie richten einen Monitor ein, erhalten zu viele Alerts und hören schließlich auf, ihnen zu vertrauen. Der bessere Ansatz ist, die Erkennung von Website-Änderungen als eine betriebliche Kontrolle zu behandeln. Jeder Alert sollte beantworten: Was hat sich geändert, warum ist es wichtig, wer ist dafür verantwortlich und was passiert als Nächstes?
Das beginnt mit der Auswahl der richtigen Oberflächen zur Überwachung.
Kartieren Sie die Web-Oberflächen, die Kunden nutzen
Nicht jede Seite verdient die gleiche Aufmerksamkeit. Ein Tippfehler in einem alten Blog-Beitrag hat selten die gleiche Dringlichkeit wie eine Preisabweichung auf einer Plan-Seite oder eine Änderung der Rückgabebestimmungen. Der beste Weg, um zu beginnen, ist, die Oberflächen zu inventarisieren, die den Umsatz, die Compliance, die Kundenerfahrung oder die Betriebsabläufe beeinflussen.
| Oberfläche zur Überwachung | Beispiele | Warum es wichtig ist | Typischer Eigentümer |
|---|
| Preis- und Verpackungsseiten | Plan-Namen, Listenpreise, Rabatte, Nutzungsgrenzen | Kunden vergleichen, kaufen und bestreiten Rechnungen auf der Grundlage dieses Textes | Umsatz-Operationen, Produkt-Marketing |
| Checkout- und Registrierungspfade | CTA-Text, Formularfelder, Zahlungshinweise, Verfügbarkeit | Kleine Änderungen können die Umwandlung verringern oder Support-Probleme verursachen | Wachstum, Web-Operationen |
| Rechtliche und Richtlinien-Seiten | Bedingungen, Datenschutzrichtlinie, Rückgaberecht, SLA-Sprache | Änderungen können Compliance- oder vertragliche Risiken schaffen | Recht, Compliance |
| Produkt-Dokumentation und Hilfe-Inhalt | Einrichtungsschritte, Funktionsverfügbarkeit, Migrationshinweise | Veraltete Anweisungen erhöhen Tickets und Kundenerfahrung | Support, Produkt |
| Lieferanten- und Partner-Seiten | Lieferanten-Bedingungen, Marktplatz-Listungen, Partner-Dokumente | Änderungen können die Lieferung, Margen oder Verpflichtungen beeinflussen | Operationen, Partnerschaften |
| Feeds und APIs | Inventar, Tarife, Partner-Feeds, Statuswerte | Strukturierte Änderungen können Downstream-Workflows brechen | Engineering, Operationen |
Dieser Kartierungs-Schritt ist der Punkt, an dem viele Überwachungs-Programme erfolgreich oder fehlschlagen. Wenn alles „kritisch“ ist, ertrinken Teams in Alerts. Wenn nur die Startseite überwacht wird, werden die höchsten Risiken verpasst.
Für ein tieferes Framework zur Priorisierung von geschäftskritischen Oberflächen ist DiffHooks Leitfaden zu wie man eine Web-Seite auf kritische Änderungen überwacht ein nützlicher Begleiter zu diesem Workflow.
Definieren Sie, was als wichtige Änderung gilt
Ein roher Diff ist nicht dasselbe wie ein nützliches Signal. Moderne Seiten ändern sich ständig. Timestamps aktualisieren, Anzeigen rotieren, Inventar-Widgets aktualisieren, Personalisierungs-Module tauschen Inhalt aus und Empfehlungs-Blöcke bewegen sich um.
Bevor Sie die Überwachung einrichten, definieren Sie, was eine Aktion auslösen sollte. Zum Beispiel kann ein Preis-Team sich um einen Dollar-Betrag, einen Prozentsatz-Rabatt oder einen Ausdruck wie „nur Jahresplan“ kümmern. Ein Compliance-Team kann sich um ein Richtlinien-Datum, Zustimmungssprache oder jurisdiktionsspezifische Formulierungen kümmern. Ein Operations-Team kann sich um einen Lieferanten-Lieferzeitraum, Mindestbestellmenge oder API-Feldwert kümmern.
Gute Änderungskriterien sind spezifisch genug, um Rauschen zu reduzieren, aber breit genug, um unerwartete Risiken zu erfassen. Anstatt „alerten Sie mich, wenn die Preis-Seite sich ändert“, ist eine bessere Regel „alerten Sie das Umsatz-Team, wenn Plan-Namen, Preise, Abrechnungsperioden, Rabatt-Bedingungen oder enthaltene Grenzen sich ändern“.
Für APIs und Feeds definieren Sie Änderungen in Bezug auf Struktur und Werte. Ein neues Feld kann harmlos sein. Ein fehlendes Feld, geändertes Status-Code, umbenanntes Attribut oder verschobener Wertebereich kann jedoch einen Workflow brechen. Das gleiche Prinzip gilt für Seiten: Ein neues Testimonial ist normalerweise niedrig priorisiert, während ein entfernter Kündigungs-Klausel dringend sein kann.
Wählen Sie die richtige Erkennungsmethode für jede Quelle
Der Ausdruck „Website-Änderungen erkennen“ umfasst mehrere unterschiedliche technische Muster. Eine öffentliche HTML-Seite, eine JavaScript-gerenderte Preis-Tabelle, ein PDF-Richtlinien-Dokument, ein RSS-Feed und ein API-Endpunkt erfordern alle unterschiedliche Behandlung.
| Quellentyp | Praktischer Überwachungsansatz | Was zu beachten ist |
|---|
| Statische Seiten | Text, HTML oder spezifische Seitenabschnitte verfolgen | Textänderungen, entfernte Abschnitte, geänderte Links |
| Dynamische Seiten | Gerenderten Inhalt oder stabile Seiten-Elemente überwachen | JavaScript-geladene Preise, Formulare, CTAs |
| Preis-Blöcke | Genau Werte und Schlüsselbegriffe verfolgen | Preisänderungen, Abrechnungsperioden, Rabatt-Bedingungen |
| Richtlinien-Seiten | Abschnitts-Text und Gültigkeitsdaten verfolgen | Bedingungs-Updates, Datenschutz-Änderungen, Rückgaberecht-Sprache |
| Feeds und APIs | Antworten, Felder, Status-Codes und Payload-Werte vergleichen | Schema-Änderungen, fehlende Daten, unerwartete Werte |
Manuelle Überprüfungen können dies nicht zuverlässig bewältigen. Sie sind langsam, inkonsistent und leicht zu übersehen, wenn Teams beschäftigt sind. Browser-Lesezeichen und Tabellenblätter können für eine Handvoll Seiten funktionieren, aber sie bieten keine schnellen Alerts, keine Historie und keine Routing.
Automatisierte Überwachung sollte der Quelle entsprechen. Für eine Richtlinien-Seite kann Text-Vergleich ausreichend sein. Für eine Preis-Seite müssen Sie möglicherweise die Plan-Tabelle isolieren und layout-bezogene Änderungen ignorieren. Für eine API müssen Sie die Antwort selbst überwachen, nicht nur, ob der Endpunkt verfügbar ist.
Wenn Ihr Anwendungsfall von der Geschwindigkeit abhängt, erklärt dieser Leitfaden zu wie man eine Seite in Echtzeit auf Änderungen überprüft, warum Echtzeit-Erkennung mehr als nur das Aktualisieren einer URL erfordert.
Passen Sie die Überwachungshäufigkeit an das Geschäftsrisiko an
Einige Seiten sollten in Echtzeit überwacht werden. Andere benötigen keine konstanten Überprüfungen. Der Schlüssel ist, die Überwachungsgeschwindigkeit mit den Kosten der Verspätung abzustimmen.
Preise, Checkout, kritische Richtlinien, hochwertige Lieferanten-Seiten und APIs, die Kunden-fokussierte Systeme speisen, verdienen normalerweise die schnellsten Alerts. Eine verzögerte Benachrichtigung kann zu Umsatzeinbußen, falschen Angeboten, gebrochenen Workflows oder vermeidbaren Kunden-Eskalationen führen.
Seiten mit geringerem Risiko, wie allgemeine Marketing-Kopie oder Evergreen-Dokumentation, benötigen möglicherweise nicht die gleiche Dringlichkeit. Sie profitieren noch von der Änderungshistorie, aber sie erfordern möglicherweise keine sofortige Eskalation.
Ein einfaches Schweregrad-Modell kann helfen:
| Schweregrad | Beispiel-Änderung | Alert-Timing | Reaktions-Erwartung |
|---|
| Kritisch | Öffentliche Preis-Abweichung, Checkout-Bruch, Richtlinien-Klausel entfernt | Sofort | Eigentümer untersucht jetzt |
| Hoch | Wettbewerber-Preis-Änderung, Lieferanten-Bedingungen-Update, API-Feld-Änderung | Schnell | Eigentümer überprüft noch am selben Tag |
| Mittel | Hilfe-Artikel-Update, nicht-kritische Seiten-Kopie-Änderung | Geplant | Überprüfung während des normalen Workflows |
| Niedrig | Layout-Anpassung, Bild-Ersatz, geringfügige Metadaten-Änderung | Digest oder Historie nur | Keine sofortige Aktion |
Dies vermeidet die häufige Falle, jede Änderung als Notfall zu behandeln. Das Ziel ist nicht, mehr Alerts zu erstellen. Das Ziel ist, frühere, vertrauenswürdigere Signale zu erstellen.
Filtern Sie Rauschen, bevor es Menschen erreicht
Rauschen ist der Feind der frühzeitigen Erkennung. Wenn ein Monitor auf jede Cookie-Banner-Variation, rotierendes Hero-Bild, Timestamp, personalisierten Block oder session-spezifische ID reagiert, werden Menschen es stummschalten. Sobald Alerts ignoriert werden, hört das Überwachungssystem auf, das Geschäft zu schützen.
Nützliche Filter hängen von der Seite und dem Team ab. Sie möchten möglicherweise Navigation, Fußzeilen, Anzeigen, verwandte Inhalte, Session-IDs, Tracking-Parameter oder Blöcke ignorieren, die bei jedem Laden ändern. Für Preise möchten Sie möglicherweise Alerts nur dann, wenn numerische Werte oder Plan-Bedingungen ändern. Für Richtlinien-Seiten möchten Sie möglicherweise Abschnitts-Änderungen anstelle von vollständigem Seiten-Rauschen.
Intelligente Filterung sollte nicht Risiken verbergen. Sie sollte vorhersehbare, niedrigwertige Änderungen entfernen, damit bedeutungsvolle Änderungen hervorstechen. Der richtige Test ist einfach: Würde der Alert jemandem helfen, eine Entscheidung zu treffen? Wenn nicht, verfeinern Sie den Monitor.
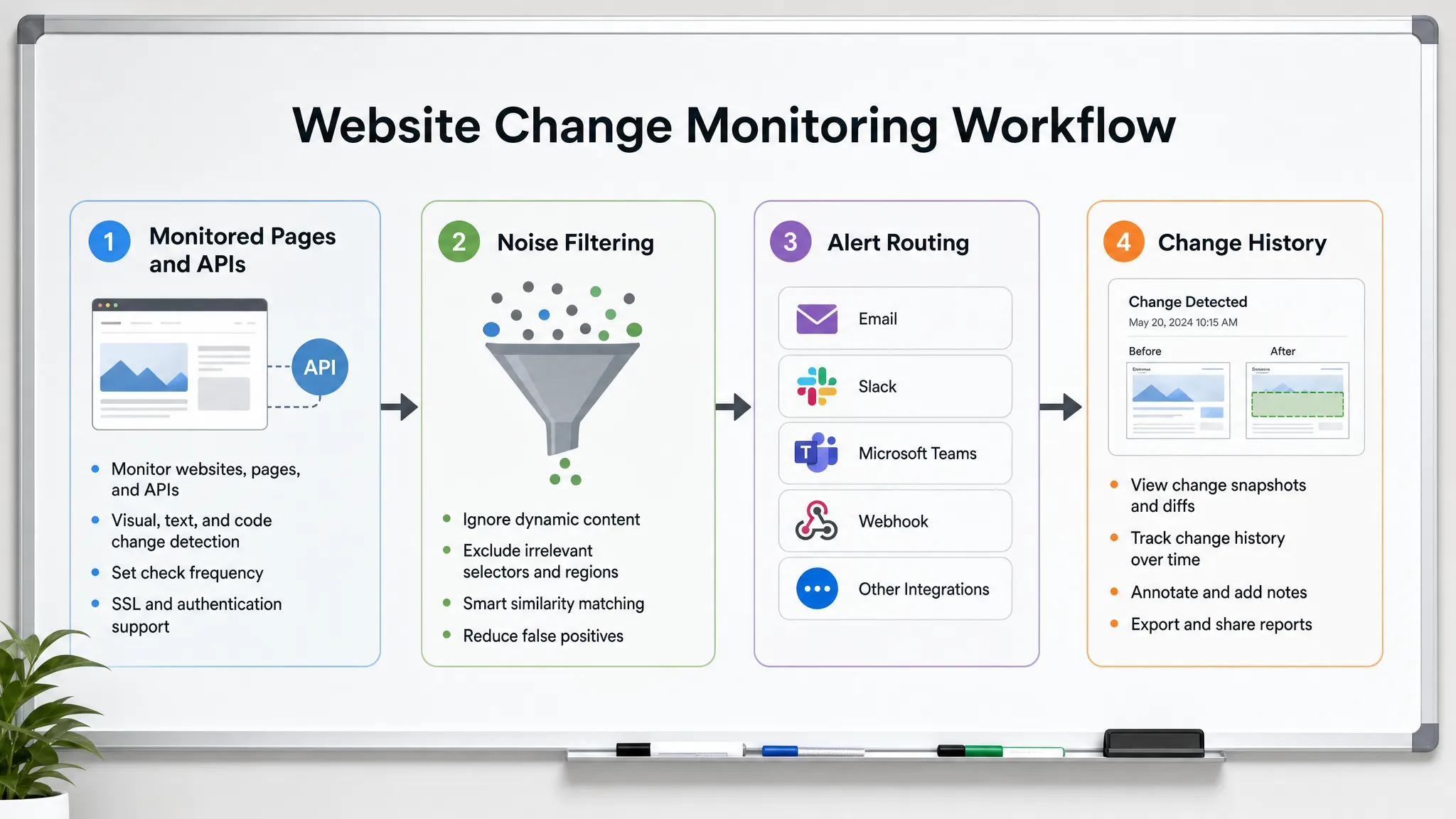
Routen Sie Alerts an die Person, die handeln kann
Eine Änderung, die schnell erkannt wird, aber an die falsche Inbox gesendet wird, ist immer noch eine verzögerte Reaktion. Alert-Routing sollte die Eigentümerschaft widerspiegeln.
Preis-Alerts sollten an Umsatz-Operationen, Produkt-Marketing oder die Person gesendet werden, die die Verpackung besitzt. Rechts-Sprache-Änderungen sollten an Recht oder Compliance gesendet werden. API- und Feed-Änderungen sollten an Engineering oder Operationen gesendet werden. Wettbewerber- oder Marktplatz-Änderungen gehören möglicherweise zu Vertrieb, Strategie oder Partnerschaften.
Die besten Alerts enthalten genug Kontext, um Rückfragen zu reduzieren:
- Die überwachte URL, Feed oder API-Endpunkt.
- Die genaue vorher/nachher-Änderung.
- Der Zeitpunkt, an dem die Änderung erkannt wurde.
- Der Schweregrad oder die Geschäftskategorie.
- Der Eigentümer oder Kanal, der für die Überprüfung verantwortlich ist.
- Der nächste Schritt, wie Validierung, Rückgängig-Machung, Eskalation oder Update interner Systeme.
Für Teams mit komplexeren operativen Stacks können Alerts Workflows in CRMs, ERPs, Ticket-Systemen oder internen Automatisierungen auslösen. Wenn Website-Änderungssignale in umfassendere Back-Office-Prozesse integriert werden müssen, kann die Zusammenarbeit mit Spezialisten für AI-Automatisierung und NetSuite-Beratung helfen, die Erkennung mit den Systemen abzustimmen, die Teams bereits nutzen, um das Geschäft zu führen.
Slack- und E-Mail-Alerts sind nützlich für die Sichtbarkeit. Webhooks und Workflow-Integrationen sind nützlich, wenn eine Änderung ein Ticket erstellen, einen Datensatz aktualisieren, ein Downstream-System benachrichtigen oder einen Überprüfungsprozess automatisch starten sollte.
Bewahren Sie eine Historie jeder bedeutungsvollen Änderung auf
Schnelle Alerts helfen Ihnen, im Moment zu reagieren. Änderungshistorie hilft Ihnen, zu verstehen, was später passiert ist.
Eine vollständige Historie ist wertvoll, wenn Teams Fragen wie diese beantworten müssen:
- Wann erschien dieser Preis zum ersten Mal?
- Was sagte die Richtlinie vor dem letzten Update?
- Hat die Lieferanten-Seite sich geändert, bevor der Kunde beschwerte?
- Welches API-Feld änderte sich, bevor der Workflow fehlschlug?
- War dies ein einmaliges Problem oder Teil eines wiederkehrenden Musters?
Ohne Historie verlassen sich Teams auf Screenshots, Erinnerungen und Chat-Threads. Das macht Incident-Überprüfungen langsamer und weniger zuverlässig. Mit einer Audit-Trail können Teams Ereignisse rekonstruieren, Änderungen im Laufe der Zeit vergleichen und Überwachungsregeln nach jedem Incident verbessern.
Historie ist besonders wichtig für compliance-sensible Teams. Das Ziel ist nicht nur, zu wissen, dass eine Seite sich geändert hat, sondern auch, Beweise für die Änderung und den Zeitpunkt der Erkennung zu bewahren.
Testen Sie den Workflow, bevor ein echter Incident eintritt
Warten Sie nicht auf eine Kundenbeschwerde, um herauszufinden, ob Ihre Überwachung funktioniert. Führen Sie kontrollierte Tests durch.
Für interne Seiten, die Sie kontrollieren, machen Sie eine kleine Test-Änderung in einem niedrig risikoreichen Bereich und bestätigen Sie, dass der richtige Alert ausgelöst wird. Für externe Seiten verwenden Sie bekannte niedrig risikoreiche Seiten, um zu validieren, dass Ihre Überwachung die Art von Inhalten erkennt, die Sie interessieren. Für APIs testen Sie erwartete Änderungen in einer Staging- oder sicheren Umgebung, wo möglich.
Dann überprüfen Sie den gesamten Pfad. Wurde die Änderung schnell genug erkannt? Wurde der Alert an die richtige Person gesendet?