Un sito web raramente fallisce in un momento drammatico. Più spesso, una linea di prezzo cambia senza preavviso, un messaggio di checkout scompare, una politica del fornitore si sposta, un concorrente aggiorna un piano o un feed restituisce un nuovo valore che rompe silenziosamente un'ipotesi all'interno del tuo business.
Se la prima persona a notarlo è un cliente, un potenziale acquirente, un partner o un ente regolatore, il costo è già più alto. Iniziano i biglietti di supporto. I team di vendita spiegano prezzi non corrispondenti. I team di conformità indagano dopo il fatto. I team operativi si affrettano a capire cosa è cambiato e quando.
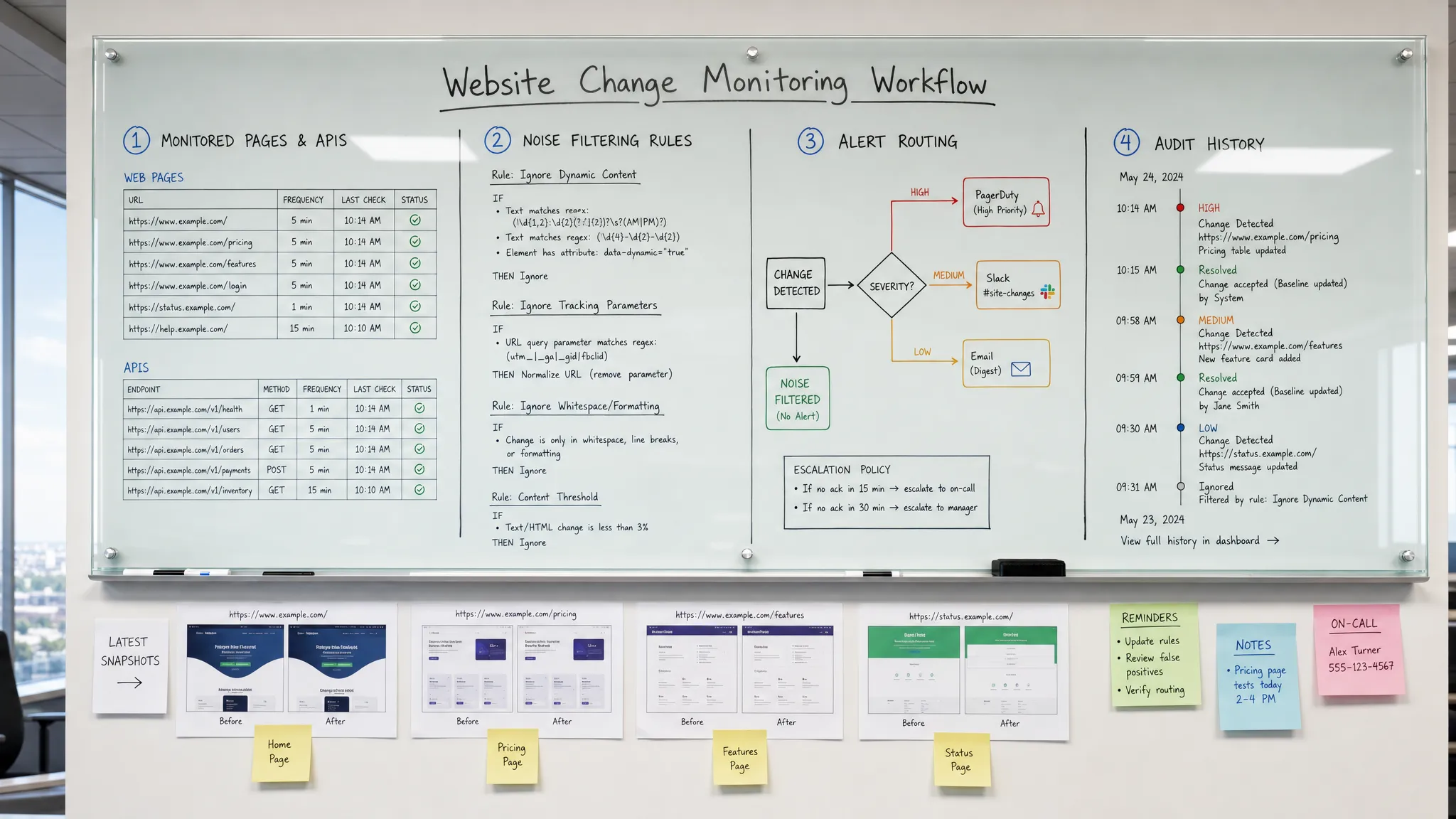
Per rilevare i cambiamenti del sito web prima che i clienti lo facciano, hai bisogno di più di uno strumento che dice "questa pagina è cambiata". Hai bisogno di un flusso di lavoro di monitoraggio che sappia quali cambiamenti sono importanti, controlli le fonti giuste alla velocità giusta, filtri il rumore e invii avvisi azionabili alle persone che possono rispondere.
Cosa significa realmente "prima dei clienti"
Rilevare i cambiamenti precocemente non è solo questione di velocità. La velocità conta, soprattutto per i prezzi, le politiche, il checkout, la disponibilità e i dati dei partner, ma è solo una parte del sistema.
Un flusso di lavoro di allarme precoce pratico dovrebbe chiudere due lacune:
- La lacuna di rilevamento, ovvero il tempo tra un cambiamento che si verifica e il tuo team che ne è a conoscenza.
- La lacuna di risposta, ovvero il tempo tra il tuo team che ne è a conoscenza e il proprietario giusto che prende azione.
Molti team si concentrano solo sulla prima lacuna. Configurano un monitor, ricevono troppi avvisi e alla fine smettono di fidarsi. L'approccio migliore è trattare la rilevazione dei cambiamenti del sito web come un controllo operativo. Ogni avviso dovrebbe rispondere: cosa è cambiato, perché è importante, chi è il proprietario e cosa succede dopo?
Ciò inizia con la scelta delle superfici giuste da monitorare.
Mappa le superfici web di cui i clienti dipendono
Non ogni pagina merita la stessa attenzione. Un errore di battitura in un vecchio post di blog raramente ha la stessa urgenza di una discrepanza di prezzo in una pagina di piano o di un cambiamento dei termini di rimborso. Il modo migliore per iniziare è inventariare le superfici che influenzano il ricavo, la conformità, l'esperienza del cliente o le operazioni.
| Superficie da monitorare | Esempi | Perché è importante | Proprietario tipico |
|---|
| Pagine di prezzi e confezionamento | Nomi dei piani, prezzi di lista, sconti, limiti di utilizzo | I clienti confrontano, acquistano e contestano le fatture in base a questa copia | Operazioni di ricavo, marketing di prodotto |
| Percorsi di checkout e registrazione | Testo del CTA, campi del modulo, avvisi di pagamento, disponibilità | Piccoli cambiamenti possono ridurre la conversione o creare problemi di supporto | Crescita, operazioni web |
| Pagine legali e di politica | Termini, politica di privacy, politica di rimborso, linguaggio SLA | I cambiamenti possono creare rischi di conformità o contrattuali | Legale, conformità |
| Documenti di prodotto e contenuti di aiuto | Passaggi di setup, disponibilità di funzionalità, note di migrazione | Istruzioni obsolete aumentano i biglietti e la frustrazione dei clienti | Supporto, prodotto |
| Pagine di fornitori e partner | Termini del fornitore, elenchi del marketplace, documenti del partner | I cambiamenti esterni possono influire sulla consegna, sui margini o sugli obblighi | Operazioni, partnership |
| Feed e API | Inventario, tariffe, feed dei partner, valori di stato | I cambiamenti strutturati possono interrompere i flussi di lavoro downstream | Ingegneria, operazioni |
Questo passaggio di mappatura è dove molti programmi di monitoraggio hanno successo o falliscono. Se tutto è "critico", i team annegano negli avvisi. Se solo la copia della homepage è monitorata, i cambiamenti a più alto rischio vengono persi.
Per un framework più approfondito sulla priorità delle superfici business-critical, la guida di DiffHook su come monitorare una pagina web per cambiamenti critici è un utile compagno a questo flusso di lavoro.
Definisci cosa conta come un cambiamento importante
Una differenza grezza non è la stessa cosa di un segnale utile. Le pagine moderne cambiano costantemente. I timestamp si aggiornano, le pubblicità ruotano, i widget di inventario si aggiornano, i moduli di personalizzazione scambiano contenuti e i blocchi di raccomandazione si spostano.
Prima di configurare il monitoraggio, definisci cosa dovrebbe attivare un'azione. Ad esempio, un team di prezzi potrebbe curarsi di un importo in dollari, di uno sconto percentuale o di una frase come "piano annuale solo". Un team di conformità potrebbe curarsi di una data di efficacia della politica, del linguaggio di consenso o di un linguaggio specifico della giurisdizione. Un team operativo potrebbe curarsi di una finestra di consegna del fornitore, di una dimensione minima dell'ordine o del valore di un campo API.
I buoni criteri di cambiamento sono abbastanza specifici da ridurre il rumore ma abbastanza ampi da catturare il rischio inaspettato. Invece di "avvisami quando la pagina dei prezzi cambia", una regola migliore è "avvisare il team di ricavo quando i nomi dei piani, i prezzi, i periodi di fatturazione, i termini di sconto o i limiti inclusi cambiano".
Per le API e i feed, definisci i cambiamenti in termini di struttura e valori. Un nuovo campo potrebbe essere innocuo. Un campo mancante, un codice di stato modificato, un attributo rinominato o un intervallo di valori spostato potrebbe interrompere un flusso di lavoro. Lo stesso principio si applica alle pagine: una nuova testimonianza è di solito a bassa priorità, mentre una clausola di cancellazione rimossa potrebbe essere urgente.
Scegli il metodo di rilevamento giusto per ogni fonte
La frase "rileva i cambiamenti del sito web" copre diversi modelli tecnici. Una pagina HTML pubblica, una tabella di prezzi renderizzata in JavaScript, un PDF di politica, un feed RSS e un endpoint API richiedono tutti un trattamento diverso.
| Tipo di fonte | Approccio di monitoraggio pratico | Cosa cercare |
|---|
| Pagine statiche | Traccia il testo, l'HTML o sezioni specifiche della pagina | Cambiamenti di copia, sezioni rimosse, link modificati |
| Pagine dinamiche | Monitora il contenuto renderizzato o elementi di pagina stabili | Prezzi caricati con JavaScript, form, CTA |
| Blocchi di prezzi | Traccia i valori esatti e i termini chiave | Cambiamenti di prezzo, periodi di fatturazione, condizioni di sconto |
| Pagine di politica | Traccia il testo a livello di sezione e le date di efficacia | Aggiornamenti dei termini, cambiamenti di privacy, linguaggio di rimborso |
| Feed e API | Confronta le risposte, i campi, i codici di stato e i valori del payload | Cambiamenti dello schema, dati mancanti, valori inaspettati |
I controlli manuali non possono gestire questo in modo affidabile. Sono lenti, inconsistenti e facili da saltare quando i team sono impegnati. I segnalibri del browser e le cartelle di lavoro potrebbero funzionare per un pugno di pagine, ma non forniscono avvisi rapidi, storia o routing.
Il monitoraggio automatizzato dovrebbe corrispondere alla fonte. Per una pagina di politica, il confronto del testo potrebbe essere sufficiente. Per una pagina di prezzi, potresti dover isolare la tabella del piano e ignorare i cambiamenti di layout non correlati. Per un'API, hai bisogno di monitorare la risposta stessa, non solo se l'endpoint è attivo.
Se il tuo caso d'uso dipende dalla velocità, questa guida su come controllare una pagina per cambiamenti in tempo reale spiega perché la rilevazione in tempo reale richiede più del semplice aggiornamento di un URL.
Abbina la frequenza di monitoraggio al rischio aziendale
Alcune pagine dovrebbero essere monitorate in tempo reale. Altre non richiedono controlli costanti. La chiave è allineare la velocità di monitoraggio con il costo di essere in ritardo.
I prezzi, il checkout, le politiche critiche, le pagine dei fornitori ad alto valore e le API che alimentano i sistemi rivolti ai clienti di solito meritano gli avvisi più rapidi. Un avviso ritardato può portare a ricavi persi, preventivi errati, flussi di lavoro interrotti o escalation dei clienti evitabili.
Le pagine a basso rischio, come la copia di marketing generale o la documentazione evergreen, potrebbero non richiedere la stessa urgenza. Tuttavia, traggono ancora beneficio dalla storia dei cambiamenti, ma potrebbero non richiedere un'escalation immediata.
Un modello di gravità semplice può aiutare:
| Gravità | Esempio di cambiamento | Timing dell'avviso | Aspettativa di risposta |
|---|
| Critico | Discrepanza di prezzo pubblico, interruzione del checkout, clausola di politica rimossa | Immediato | Il proprietario indaga ora |
| Alto | Cambiamento del prezzo di un concorrente, aggiornamento dei termini del fornitore, cambiamento del campo API | Rapido | Il proprietario esamina lo stesso giorno |
| Medio | Aggiornamento dell'articolo di aiuto, cambiamento di copia di pagina non critica | Programmato | Esamina durante il flusso di lavoro normale |
| Basso | Regolazione del layout, sostituzione dell'immagine, cambiamento minore dei metadati | Solo storia o riepilogo | Nessuna azione immediata |
Ciò evita la trappola comune di trattare ogni cambiamento come un'emergenza. L'obiettivo non è creare più avvisi. L'obiettivo è creare segnali più precoci e più affidabili.
Filtra il rumore prima che raggiunga le persone
Il rumore è il nemico della rilevazione precoce. Se un monitor avvisa per ogni variazione del banner dei cookie, dell'immagine eroe rotante, del timestamp o del blocco personalizzato, le persone lo silenzieranno. Una volta che gli avvisi vengono ignorati, il sistema di monitoraggio smette di proteggere l'azienda.
I filtri utili dipendono dalla pagina e dal team. Potresti voler ignorare la navigazione, i footer, le pubblicità, i contenuti correlati, gli ID di sessione, i parametri di tracciamento o i blocchi che cambiano ad ogni caricamento. Per i prezzi, potresti voler avvisi solo quando i valori numerici o i termini del piano cambiano. Per le pagine di politica, potresti voler diff di livello di sezione invece di rumore di pagina completa.
La filtrazione intelligente non dovrebbe nascondere il rischio. Dovrebbe rimuovere i cambiamenti prevedibili e a basso valore in modo che i cambiamenti significativi spicchino. Il test giusto è semplice: l'avviso aiuterebbe qualcuno a prendere una decisione? Se no, raffina il monitor.
Inoltra gli avvisi alla persona che può agire
Un cambiamento rilevato rapidamente ma inviato alla casella di posta sbagliata è ancora una risposta ritardata. L'inoltro degli avvisi dovrebbe riflettere la proprietà.
Gli avvisi di prezzo dovrebbero andare alle operazioni di ricavo, al marketing del prodotto o alla persona che possiede il confezionamento. I cambiamenti del linguaggio legale dovrebbero andare al legale o alla conformità. I cambiamenti dell'API e del feed dovrebbero andare all'ingegneria o alle operazioni. I cambiamenti dei concorrenti o del marketplace potrebbero appartenere alle vendite, alla strategia o ai partnership.
Gli avvisi migliori includono abbastanza contesto per ridurre l'andirivieni:
- L'URL monitorato, il feed o l'endpoint API.
- Il cambiamento esatto prima e dopo.
- L'orario in cui il cambiamento è stato rilevato.
- La gravità o la categoria aziendale.
- Il proprietario o il canale responsabile della revisione.
- Il passo successivo, come convalidare, revertire, escalare o aggiornare i sistemi interni.
Per i team con stack operativi più complessi, gli avvisi potrebbero dover attivare flussi di lavoro in CRM, ERP, sistemi di ticketing o automazione interna. Se i segnali di cambiamento del sito web devono collegarsi ai processi back-office più ampi, lavorare con specialisti in automazione AI e consulenza NetSuite può aiutare ad allineare la rilevazione con i sistemi che i team già utilizzano per gestire l'azienda.
Gli avvisi di Slack e di posta elettronica sono utili per la visibilità. I webhook e le integrazioni del flusso di lavoro sono utili quando un cambiamento dovrebbe creare un ticket, aggiornare un record, notificare un sistema downstream o avviare automaticamente un processo di revisione.
Conserva una storia di ogni cambiamento significativo
Gli avvisi rapidi aiutano a rispondere nel momento. La storia dei cambiamenti aiuta a comprendere cosa è successo in seguito.
Una storia completa è preziosa quando i team devono rispondere a domande come:
- Quando è apparso per la prima volta questo prezzo?
- Cosa diceva la politica prima dell'ultimo aggiornamento?
- La pagina del fornitore è cambiata prima della lamentela del cliente?
- Quale campo API è cambiato prima che il flusso di lavoro si interrompesse?
- È stato un problema una tantum o parte di un modello ricorrente?
Senza storia, i team si affidano a screenshot, memoria e thread di chat. Ciò rende le revisioni degli incidenti più lente e meno affidabili. Con un registro di audit, i team possono ricostruire gli eventi, confrontare i cambiamenti nel tempo e migliorare le regole di monitoraggio dopo ogni incidente.
La storia è particolarmente importante per i team sensibili alla conformità. L'obiettivo non è solo sapere che una pagina è cambiata, ma preservare le prove di cosa è cambiato e quando è stato rilevato.
Testa il flusso di lavoro prima di un incidente reale
Non aspettare una lamentela del cliente per scoprire se il monitoraggio funziona. Esegui test controllati.
Per le pagine interne che controlli, apporta un piccolo cambiamento di test in un'area a basso rischio e conferma che l'avviso giusto si attiva. Per le pagine esterne, utilizza pagine note a basso rischio per convalidare che il monitoraggio rileva il tipo di contenuto di cui ti importa. Per le API, testa i cambiamenti attesi in un ambiente di staging o sicuro quando possibile.
Quindi esamina l'intero percorso. Il cambiamento è stato rilevato abbastanza rapidamente? L'avviso è stato inviato alla persona giusta? Il team ha risposto in modo tempestivo?