Un site Web rarement échoue en un moment dramatique. Plus souvent, une ligne de tarification change sans préavis, un message de checkout disparaît, une politique de fournisseur change, un concurrent met à jour un plan ou un flux retourne une nouvelle valeur qui brise discrètement une hypothèse à l'intérieur de votre entreprise.
Si la première personne à remarquer est un client, un prospect, un partenaire ou un régulateur, le coût est déjà plus élevé. Les tickets de support commencent. Les équipes de vente expliquent les tarifs non correspondants. Les équipes de conformité enquêtent après les faits. Les équipes d'exploitation se précipitent pour comprendre ce qui a changé et quand.
Pour détecter les changements de site Web avant que les clients ne le fassent, vous avez besoin de plus qu'un outil qui dit « cette page a changé ». Vous avez besoin d'un flux de travail de surveillance qui sait quels changements sont importants, vérifie les bonnes sources à la bonne vitesse, filtre le bruit et envoie des alertes actionnables aux personnes qui peuvent réagir.
Ce que « avant les clients » signifie vraiment
La détection précoce des changements n'est pas seulement une question de rapidité. La rapidité est importante, en particulier pour les tarifs, les politiques, les checkout, la disponibilité et les données des partenaires, mais ce n'est qu'une partie du système.
Un flux de travail d'alerte précoce pratique devrait combler deux lacunes :
- L'écart de détection, c'est-à-dire le temps entre un changement et le moment où votre équipe en est informée.
- L'écart de réponse, c'est-à-dire le temps entre le moment où votre équipe est informée et le moment où le propriétaire approprié prend des mesures.
De nombreuses équipes se concentrent uniquement sur la première lacune. Elles configurent un moniteur, reçoivent trop d'alertes et finissent par ne plus leur faire confiance. La meilleure approche consiste à traiter la détection des changements de site Web comme un contrôle opérationnel. Chaque alerte devrait répondre à ces questions : qu'est-ce qui a changé, pourquoi cela est-il important, qui en est responsable et que se passe-t-il ensuite ?
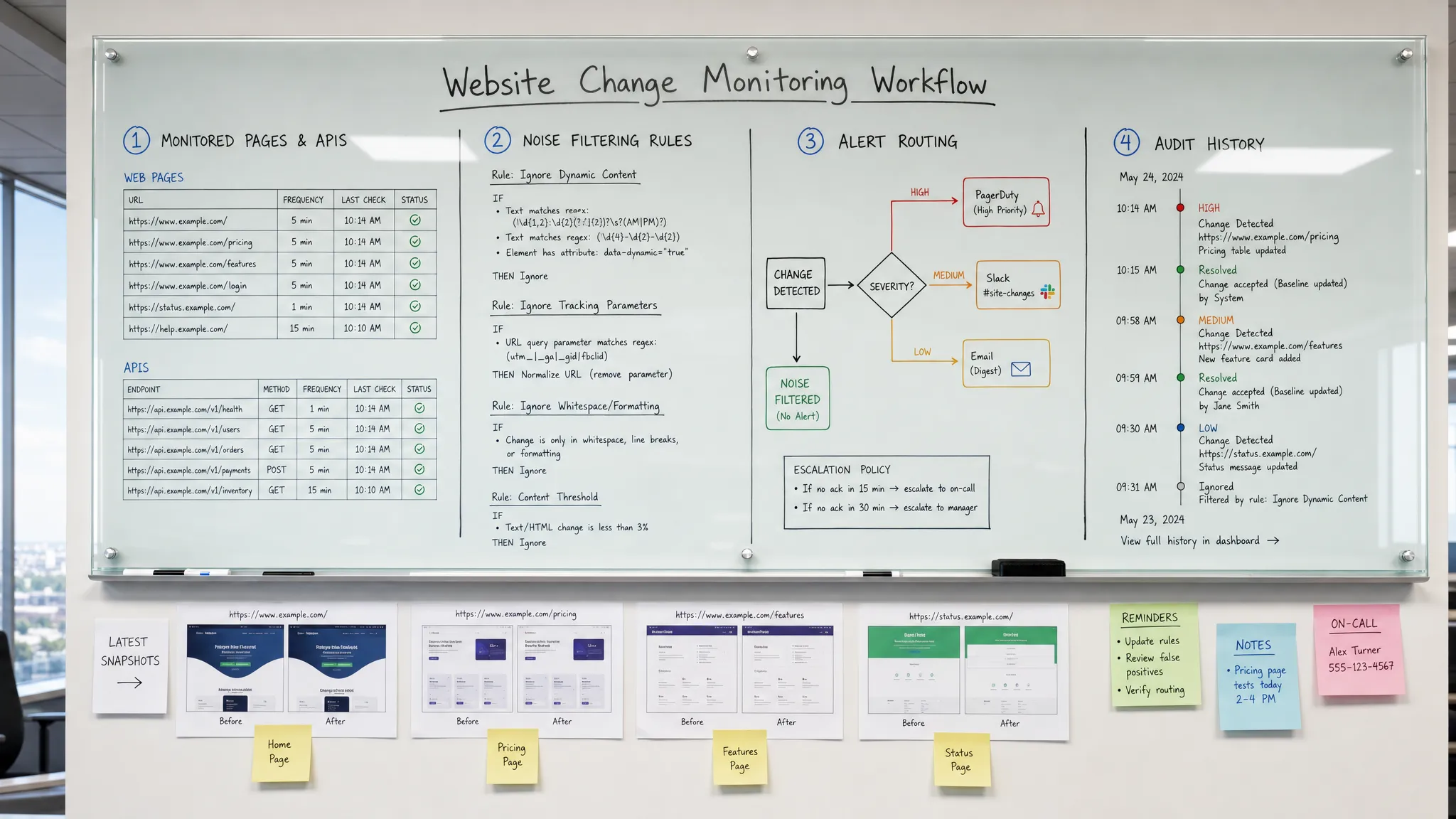
Cela commence par le choix des surfaces à surveiller.
Cartographier les surfaces Web sur lesquelles les clients comptent
Toutes les pages ne méritent pas la même attention. Une faute de frappe sur un ancien billet de blogue rarement a la même urgence qu'une erreur de tarification sur une page de plan ou un changement des conditions de remboursement. La meilleure façon de commencer est d'inventorier les surfaces qui influencent les revenus, la conformité, l'expérience client ou les opérations.
| Surface à surveiller | Exemples | Pourquoi cela est important | Propriétaire typique |
|---|
| Pages de tarification et de conditionnement | Noms de plans, tarifs listés, remises, limites d'utilisation | Les clients comparent, achètent et contestent les factures en fonction de cette copie | Opérations de revenu, marketing de produit |
| Chemins de checkout et d'inscription | Texte de CTA, champs de formulaire, notifications de paiement, disponibilité | De petits changements peuvent réduire la conversion ou créer des problèmes de support | Croissance, opérations Web |
| Pages juridiques et politiques | Conditions, politique de confidentialité, politique de remboursement, langage de SLA | Les changements peuvent créer des risques de conformité ou contractuels | Juridique, conformité |
| Documentation de produit et contenu d'aide | Étapes de configuration, disponibilité des fonctionnalités, notes de migration | Les instructions obsolètes augmentent les tickets et la frustration des clients | Support, produit |
| Pages de fournisseurs et de partenaires | Conditions de fournisseur, listes de marché, documents de partenariat | Les changements externes peuvent affecter la livraison, les marges ou les obligations | Opérations, partenariats |
| Flux et API | Inventaire, taux, flux de partenaires, valeurs de statut | Les changements structurés peuvent briser les flux de travail en aval | Ingénierie, opérations |
Cette étape de cartographie est celle où de nombreux programmes de surveillance réussissent ou échouent. Si tout est « critique », les équipes se noient dans les alertes. Si seule la copie de la page d'accueil est surveillée, les changements les plus à risque sont manqués.
Pour un cadre plus approfondi sur la priorisation des surfaces commerciales critiques, le guide de DiffHook sur comment surveiller une page Web pour les changements critiques est un compagnon utile pour ce flux de travail.
Définir ce qui constitue un changement important
Un diff brut n'est pas la même chose qu'un signal utile. Les pages modernes changent constamment. Les horodatages sont mis à jour, les publicités tournent, les widgets d'inventaire sont actualisés, les modules de personnalisation échangent du contenu et les blocs de recommandation se déplacent.
Avant de configurer la surveillance, définissez ce qui devrait déclencher une action. Par exemple, une équipe de tarification peut se soucier d'un montant en dollars, d'un pourcentage de remise ou d'une phrase telle que « plan annuel uniquement ». Une équipe de conformité peut se soucier d'une date d'entrée en vigueur de la politique, d'un langage de consentement ou de libellés spécifiques à la juridiction. Une équipe d'exploitation peut se soucier de la fenêtre de livraison d'un fournisseur, de la taille de commande minimale ou de la valeur d'un champ d'API.
De bons critères de changement sont suffisamment spécifiques pour réduire le bruit, mais suffisamment larges pour attraper des risques inattendus. Au lieu de « m'alerter lorsque la page de tarification change », une meilleure règle est « alerter l'équipe de revenu lorsque les noms de plan, les tarifs, les périodes de facturation, les conditions de remise ou les limites incluses changent ».
Pour les API et les flux, définissez les changements en termes de structure et de valeurs. Un nouveau champ peut être inoffensif. Un champ manquant, un code de statut modifié, un attribut renommé ou une plage de valeurs déplacée peut briser un flux de travail. Le même principe s'applique aux pages : un nouveau témoignage est généralement de faible priorité, tandis qu'une clause de résiliation supprimée peut être urgente.
Choisir la bonne méthode de détection pour chaque source
L'expression « détecter les changements de site Web » couvre plusieurs modèles techniques différents. Une page HTML publique, un tableau de tarification rendu par JavaScript, un document PDF de politique, un flux RSS et un point de terminaison d'API nécessitent tous des manipulations différentes.
| Type de source | Approche de surveillance pratique | Ce à quoi prêter attention |
|---|
| Pages statiques | Suivre le texte, le HTML ou des sections spécifiques de page | Changements de copie, sections supprimées, liens modifiés |
| Pages dynamiques | Surveiller le contenu rendu ou des éléments de page stables | Tarifs chargés par JavaScript, formulaires, CTA |
| Blocs de tarification | Suivre les valeurs exactes et les termes clés | Changements de tarifs, périodes de facturation, conditions de remise |
| Pages de politique | Suivre le texte au niveau de la section et les dates d'entrée en vigueur | Mises à jour des conditions, changements de confidentialité, langage de remboursement |
| Flux et API | Comparer les réponses, les champs, les codes de statut et les valeurs de charge utile | Changements de schéma, données manquantes, valeurs inattendues |
Les vérifications manuelles ne peuvent pas gérer cela de manière fiable. Elles sont lentes, incohérentes et faciles à sauter lorsque les équipes sont occupées. Les signets de navigateur et les tableurs peuvent fonctionner pour une poignée de pages, mais ils ne fournissent pas d'alertes rapides, d'historique ou de routage.
La surveillance automatisée devrait correspondre à la source. Pour une page de politique, la comparaison de texte peut suffire. Pour une page de tarification, vous pouvez avoir besoin d'isoler le tableau de plan et d'ignorer les changements de disposition non liés. Pour une API, vous devez surveiller la réponse elle-même, et non seulement si le point de terminaison est actif.
Si votre cas d'utilisation dépend de la rapidité, ce guide pour vérifier une page pour les changements en temps réel explique pourquoi la détection en temps réel nécessite plus que simplement rafraîchir une URL.
Faire correspondre la fréquence de surveillance au risque commercial
Certaines pages devraient être surveillées en temps réel. D'autres n'ont pas besoin de vérifications constantes. La clé est d'aligner la vitesse de surveillance sur le coût de la lenteur.
Les tarifs, les checkout, les politiques critiques, les pages de fournisseurs à haute valeur et les API qui alimentent les systèmes orientés client méritent généralement les alertes les plus rapides. Un avis retardé peut entraîner des pertes de revenus, des devis incorrects, des flux de travail brisés ou des escalades de clients évitables.
Les pages à risque plus faible, telles que la copie de marketing générale ou la documentation evergreen, n'ont peut-être pas besoin de la même urgence. Elles bénéficient toujours de l'historique des changements, mais elles peuvent ne pas nécessiter d'escalade immédiate.
Un modèle de gravité simple peut aider :
| Gravité | Exemple de changement | Délai d'alerte | Attente de réponse |
|---|
| Critique | Erreur de tarification publique, rupture de checkout, clause de politique supprimée | Immédiat | Propriétaire enquête maintenant |
| Élevé | Changement de tarification d'un concurrent, mise à jour des conditions de fournisseur, changement de champ d'API | Rapide | Propriétaire examine le même jour |
| Moyen | Mise à jour de l'article d'aide, changement de copie de page non critique | Planifié | Examinez pendant le flux de travail normal |
| Faible | Réglage de disposition, remplacement d'image, changement mineur de métadonnées | Résumé ou historique uniquement | Aucune action immédiate |
Cela évite le piège courant de traiter chaque changement comme une urgence. L'objectif n'est pas de créer plus d'alertes. L'objectif est de créer des signaux plus précoces et plus fiables.
Filtrez le bruit avant qu'il ne parvienne aux personnes
Le bruit est l'ennemi de la détection précoce. Si un moniteur alerte sur chaque variation de bannière de cookies, d'image héroïque tournante, d'horodatage, de bloc personnalisé ou de bloc de recommandation, les gens vont le mettre en sourdine. Une fois les alertes ignorées, le système de surveillance cesse de protéger l'entreprise.
Les filtres utiles dépendent de la page et de l'équipe. Vous pouvez vouloir ignorer la navigation, les pieds de page, les publicités, le contenu lié, les ID de session, les paramètres de suivi ou les blocs qui changent à chaque chargement. Pour les tarifs, vous pouvez vouloir des alertes uniquement lorsque les valeurs numériques ou les termes de plan changent. Pour les pages de politique, vous pouvez vouloir des différences au niveau de la section plutôt que du bruit de page complet.
Un filtrage intelligent ne devrait pas cacher les risques. Il devrait supprimer les changements prévisibles et de faible valeur afin que les changements significatifs se démarquent. Le bon test est simple : l'alerte aiderait-elle quelqu'un à prendre une décision ? Si ce n'est pas le cas, affinez le moniteur.
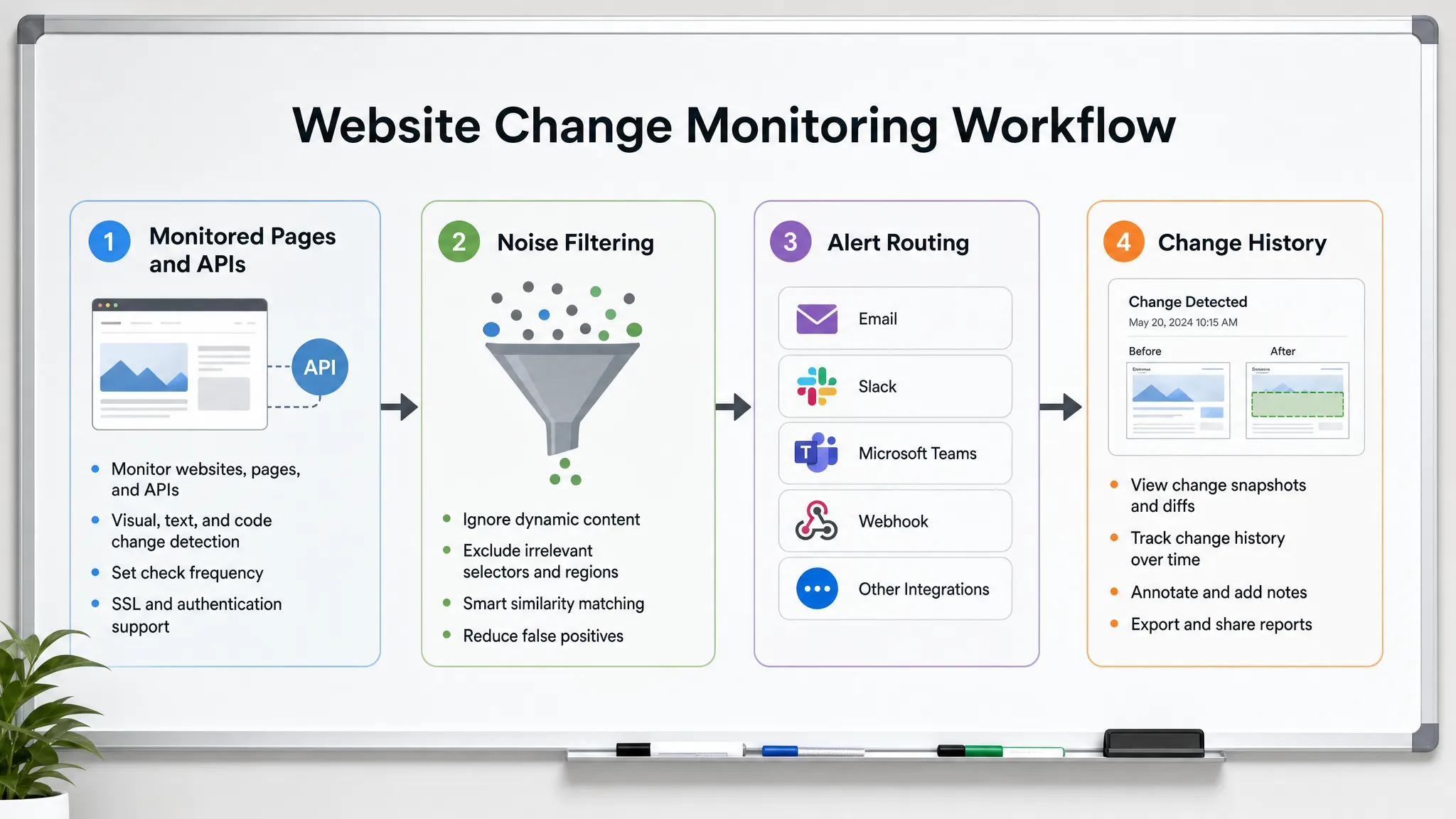
Acheminez les alertes vers la personne qui peut agir
Un changement détecté rapidement mais envoyé à la mauvaise boîte de réception est toujours une réponse retardée. Le routage des alertes devrait refléter la propriété.
Les alertes de tarification devraient aller aux opérations de revenu, au marketing de produit ou à la personne qui possède l'emballage. Les changements de langage juridique devraient aller au service juridique ou à la conformité. Les changements d'API et de flux devraient aller à l'ingénierie ou aux opérations. Les changements de concurrent ou de marché peuvent appartenir aux ventes, à la stratégie ou aux partenariats.
Les meilleures alertes incluent suffisamment de contexte pour réduire les allers-retours :
- L'URL surveillée, le flux ou le point de terminaison d'API.
- Le changement avant et après exact.
- L'heure à laquelle le changement a été détecté.
- La gravité ou la catégorie commerciale.
- Le propriétaire ou le canal responsable de l'examen.
- L'étape suivante, telle que valider, révertir, escalader ou mettre à jour les systèmes internes.
Pour les équipes avec des piles opérationnelles plus complexes, les alertes peuvent nécessiter de déclencher des flux de travail dans les CRM, les ERP, les systèmes de ticketing ou l'automatisation interne. Si les signaux de changement de site Web doivent se connecter aux processus de back-office plus larges, travailler avec des spécialistes de l'automatisation de l'IA et de la consultation NetSuite peut aider à aligner la détection sur les systèmes que les équipes utilisent déjà pour faire fonctionner l'entreprise.
Les alertes Slack et e-mail sont utiles pour la visibilité. Les webhooks et les intégrations de flux de travail sont utiles lorsque un changement doit créer un ticket, mettre à jour un enregistrement, notifier un système en aval ou démarrer un processus d'examen automatiquement.
Conservez un historique de chaque changement significatif
Les alertes rapides aident à réagir sur le moment. L'historique des changements aide à comprendre ce qui s'est passé plus tard.
Un historique complet est précieux lorsque les équipes ont besoin de répondre à des questions telles que :
- Quand ce prix est-il apparu pour la première fois ?
- Qu'est-ce que la politique disait avant la dernière mise à jour ?
- La page du fournisseur a-t-elle changé avant la plainte du client ?
- Quel champ d'API a changé avant que le flux de travail ne soit interrompu ?
- S'agissait-il d'un problème unique ou d'une partie d'un modèle récurrent ?
Sans historique, les équipes s'appuient sur des captures d'écran, la mémoire et les fils de discussion. Cela rend les examens d'incident plus lents et moins fiables. Avec une traçabilité, les équipes peuvent reconstruire les événements, comparer les changements au fil du temps et améliorer les règles de surveillance après chaque incident.
L'historique est particulièrement important pour les équipes sensibles à la conformité. L'objectif n'est pas seulement de savoir qu'une page a changé, mais de préserver des preuves de ce qui a changé et quand il a été détecté.
Testez le flux de travail avant un incident réel
N'attendez pas une plainte de client pour découvrir si votre surveillance fonctionne. Exécutez des tests contrôlés.
Pour les pages internes que vous contrôlez, effectuez un petit changement de test dans une zone à faible risque et confirmez que l'alerte appropriée se déclenche. Pour les pages externes, utilisez des pages à faible risque connues pour valider que votre surveillance détecte le type de contenu qui vous intéresse. Pour les API, testez les changements attendus dans un environnement de staging ou sûr lorsque cela est possible.
Examinez ensuite le chemin complet. Le changement a-t-il été détecté suffisamment rapidement ? L'alerte a-t-elle été acheminée vers la bonne personne ? Le propriétaire a-t-il réagi comme prévu ?