Um site raramente falha em um momento dramático. Mais frequentemente, uma linha de preços muda sem aviso, uma mensagem de checkout some, uma política de fornecedor muda, um concorrente atualiza um plano ou uma alimentação retorna um novo valor que quebra silenciosamente uma suposição dentro do seu negócio.
Se a primeira pessoa a notar for um cliente, prospect, parceiro ou regulador, o custo já é maior. Ingressam tickets de suporte. Equipes de vendas explicam preços desatualizados. Equipes de conformidade investigam após o fato. Equipes de operações se apressam para entender o que mudou e quando.
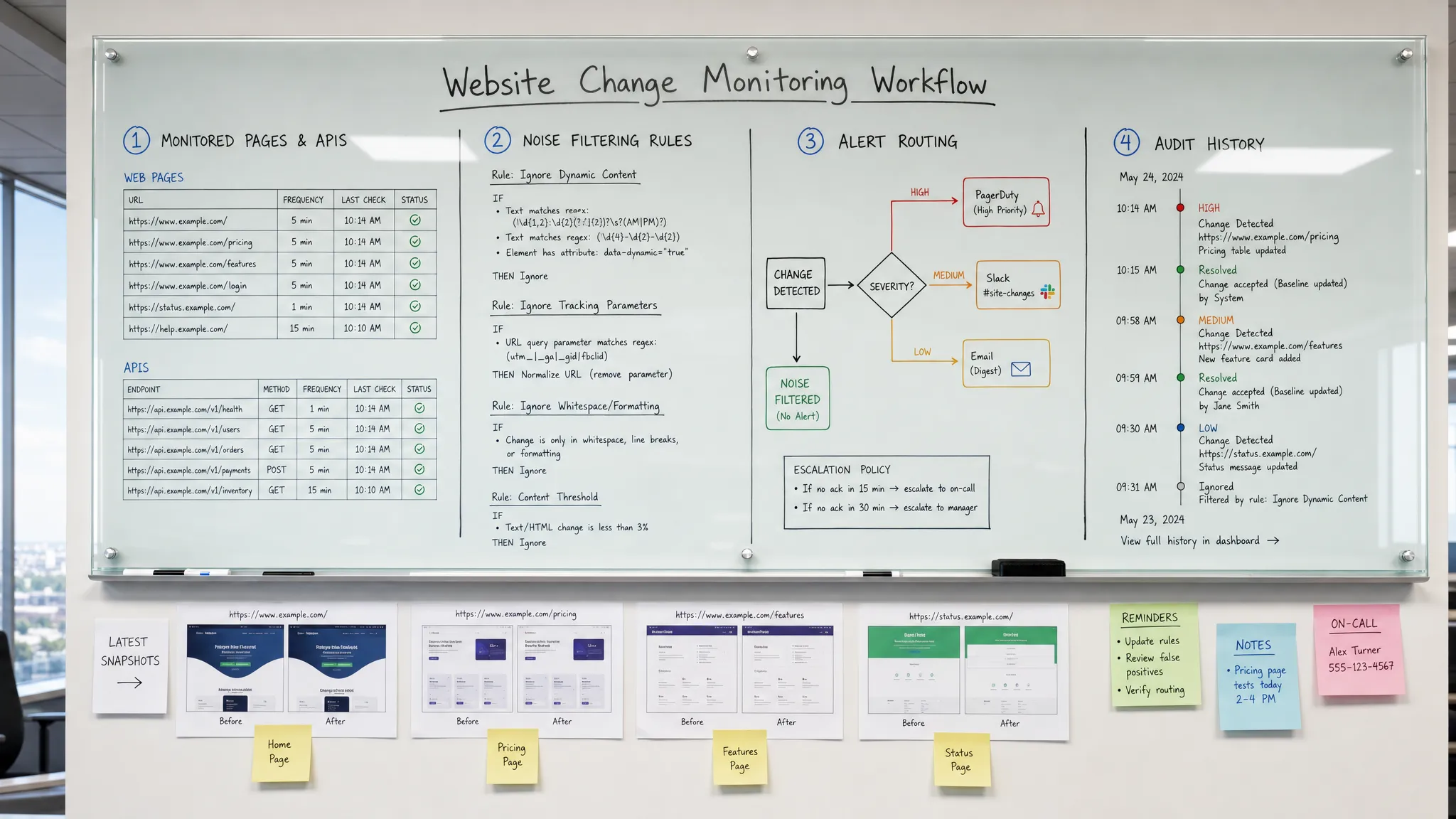
Para detectar mudanças no site antes que os clientes o façam, você precisa de mais do que uma ferramenta que diga "essa página mudou". Você precisa de um fluxo de trabalho de monitoramento que saiba quais mudanças importam, verifique as fontes certas na velocidade certa, filtre o ruído e envie alertas acionáveis para as pessoas que podem responder.
O que "antes que os clientes" realmente significa
Detectar mudanças precocemente não é apenas sobre velocidade. A velocidade importa, especialmente para preços, políticas, checkout, disponibilidade e dados de parceiros, mas é apenas uma parte do sistema.
Um fluxo de trabalho de alerta precoce prático deve fechar duas lacunas:
- A lacuna de detecção, significando o tempo entre uma mudança ocorrer e sua equipe saber sobre ela.
- A lacuna de resposta, significando o tempo entre sua equipe saber e o proprietário certo tomar ação.
Muitas equipes se concentram apenas na primeira lacuna. Elas configuram um monitor, recebem muitos alertas e eventualmente param de confiar neles. A abordagem melhor é tratar a detecção de mudanças no site como um controle operacional. Cada alerta deve responder: o que mudou, por que isso importa, quem é o proprietário e o que acontece em seguida?
Isso começa com a escolha das superfícies certas para monitorar.
Mapear as superfícies da web que os clientes dependem
Não toda página merece a mesma atenção. Um erro de digitação em uma postagem de blog antiga raramente tem a mesma urgência que uma incompatibilidade de preços em uma página de plano ou uma mudança nos termos de reembolso. A melhor maneira de começar é inventariar as superfícies que influenciam receita, conformidade, experiência do cliente ou operações.
| Superfície para monitorar | Exemplos | Por que isso importa | Proprietário típico |
|---|
| Páginas de preços e embalagens | Nomes de planos, preços de lista, descontos, limites de uso | Clientes comparam, compram e desafiam faturas com base nessa cópia | Operações de receita, marketing de produto |
| Caminhos de checkout e cadastro | Texto de CTA, campos de formulário, avisos de pagamento, disponibilidade | Pequenas mudanças podem reduzir a conversão ou criar problemas de suporte | Crescimento, operações da web |
| Páginas legais e de política | Termos, política de privacidade, política de reembolso, linguagem de SLA | Mudanças podem criar risco de conformidade ou contratual | Legal, conformidade |
| Documentos de produto e conteúdo de ajuda | Etapas de configuração, disponibilidade de recursos, notas de migração | Instruções desatualizadas aumentam os tickets e a frustração do cliente | Suporte, produto |
| Páginas de fornecedores e parceiros | Termos de fornecedor, listagens de mercado, documentos de parceiro | Mudanças externas podem afetar a entrega, margens ou obrigações | Operações, parcerias |
| Alimentações e APIs | Inventário, taxas, alimentações de parceiro, valores de status | Mudanças estruturadas podem quebrar fluxos de trabalho downstream | Engenharia, operações |
Esta etapa de mapeamento é onde muitos programas de monitoramento têm sucesso ou falham. Se tudo for "crítico", as equipes se afogam em alertas. Se apenas a cópia da página inicial for monitorada, as mudanças de maior risco são perdidas.
Para um quadro de trabalho mais profundo sobre a priorização de superfícies de negócios críticas, o guia da DiffHook sobre como monitorar uma página da web para mudanças críticas é um acompanhante útil para este fluxo de trabalho.
Definir o que conta como uma mudança importante
Um diff bruto não é o mesmo que um sinal útil. Páginas modernas mudam constantemente. Timestamps são atualizados, anúncios giram, widgets de inventário são atualizados, módulos de personalização trocam conteúdo e blocos de recomendação se movem.
Antes de configurar o monitoramento, defina o que deve acionar a ação. Por exemplo, uma equipe de preços pode se importar com um valor em dólar, um desconto percentual ou uma frase como "plano anual apenas". Uma equipe de conformidade pode se importar com uma data de vigência de política, linguagem de consentimento ou redação específica da jurisdição. Uma equipe de operações pode se importar com a janela de entrega de um fornecedor, tamanho de pedido mínimo ou valor de campo de API.
Boas critérios de mudança são específicos o suficiente para reduzir o ruído, mas amplos o suficiente para capturar riscos inesperados. Em vez de "alerte-me quando a página de preços mudar", uma regra melhor é "alerte a equipe de receita quando os nomes de plano, preços, períodos de faturamento, termos de desconto ou limites incluídos mudarem".
Para APIs e alimentações, defina mudanças em termos de estrutura e valores. Um novo campo pode ser inofensivo. Um campo ausente, código de status alterado, atributo renomeado ou faixa de valor alterada pode quebrar um fluxo de trabalho. O mesmo princípio se aplica a páginas: um novo testemunho é geralmente de baixa prioridade, enquanto uma cláusula de cancelamento removida pode ser urgente.
Escolher o método de detecção certo para cada fonte
A frase "detectar mudanças no site" cobre vários padrões técnicos diferentes. Uma página HTML pública, uma tabela de preços renderizada em JavaScript, um PDF de política, uma alimentação RSS e um ponto de extremidade de API todos requerem manipulação diferente.
| Tipo de fonte | Abordagem de monitoramento prática | O que observar |
|---|
| Páginas estáticas | Rastrear texto, HTML ou seções específicas de página | Mudanças de cópia, seções removidas, links alterados |
| Páginas dinâmicas | Monitorar conteúdo renderizado ou elementos de página estáveis | Preços carregados em JavaScript, formulários, CTAs |
| Blocos de preços | Rastrear valores exatos e termos-chave | Mudanças de preços, períodos de faturamento, condições de desconto |
| Páginas de política | Rastrear texto de nível de seção e datas de vigência | Atualizações de termos, mudanças de privacidade, linguagem de reembolso |
| Alimentações e APIs | Comparar respostas, campos, códigos de status e valores de payload | Mudanças de esquema, dados ausentes, valores inesperados |
Verificações manuais não podem lidar com isso de forma confiável. Elas são lentas, inconsistentes e fáceis de saltar quando as equipes estão ocupadas. Favoritos do navegador e planilhas podem funcionar para um punhado de páginas, mas não fornecem alertas rápidos, histórico ou roteamento.
O monitoramento automatizado deve corresponder à fonte. Para uma página de política, a comparação de texto pode ser suficiente. Para uma página de preços, você pode precisar isolar a tabela de planos e ignorar mudanças de layout não relacionadas. Para uma API, você precisa monitorar a resposta em si, não apenas se o ponto de extremidade está funcionando.
Se o seu caso de uso depende da velocidade, este guia para verificar uma página para mudanças em tempo real explica por que a detecção em tempo real requer mais do que simplesmente atualizar uma URL.
Combinar a frequência de monitoramento com o risco comercial
Algumas páginas devem ser monitoradas em tempo real. Outras não precisam de verificações constantes. A chave é alinhar a velocidade de monitoramento com o custo de ser atrasado.
Preços, checkout, políticas críticas, páginas de fornecedores de alto valor e APIs que alimentam sistemas voltados para o cliente geralmente merecem os alertas mais rápidos. Um aviso atrasado pode levar a receita perdida, cotações incorretas, fluxos de trabalho quebrados ou escaladas de cliente evitáveis.
Páginas de risco mais baixo, como cópia de marketing geral ou documentação evergreen, podem não precisar da mesma urgência. Elas ainda se beneficiam do histórico de mudanças, mas podem não requerer escalada imediata.
Um modelo de gravidade simples pode ajudar:
| Gravidade | Exemplo de mudança | Tempo de alerta | Expectativa de resposta |
|---|
| Crítico | Incompatibilidade de preços pública, quebra de checkout, cláusula de política removida | Imediato | Proprietário investiga agora |
| Alto | Mudança de preços de concorrente, atualização de termos de fornecedor, mudança de campo de API | Rápido | Proprietário revisa no mesmo dia |
| Médio | Atualização de artigo de ajuda, mudança de cópia de página não crítica | Agendado | Revisão durante o fluxo de trabalho normal |
| Baixo | Ajuste de layout, substituição de imagem, mudança de metadados menor | Resumo ou histórico apenas | Nenhuma ação imediata |
Isso evita a armadilha comum de tratar cada mudança como uma emergência. O objetivo não é criar mais alertas. O objetivo é criar sinais antecipados e mais confiáveis.
Filtrar o ruído antes que ele alcance as pessoas
O ruído é o inimigo da detecção antecipada. Se um monitor alertar sobre cada variação de banner de cookie, imagem de herói giratória, timestamp ou bloco personalizado, as pessoas o silenciarão. Uma vez que os alertas sejam ignorados, o sistema de monitoramento para de proteger o negócio.
Use filtros úteis que dependam da página e da equipe. Você pode querer ignorar navegação, rodapés, anúncios, conteúdo relacionado, IDs de sessão, parâmetros de rastreamento ou blocos que mudam a cada carregamento. Para preços, você pode querer alertas apenas quando valores numéricos ou termos de plano mudam. Para páginas de política, você pode querer diferenças de nível de seção em vez de ruído de página completa.
Filtragem inteligente não deve esconder risco. Deve remover mudanças previsíveis e de baixo valor para que mudanças significativas se destaquem. O teste certo é simples: o alerta ajudaria alguém a tomar uma decisão? Se não, refine o monitor.
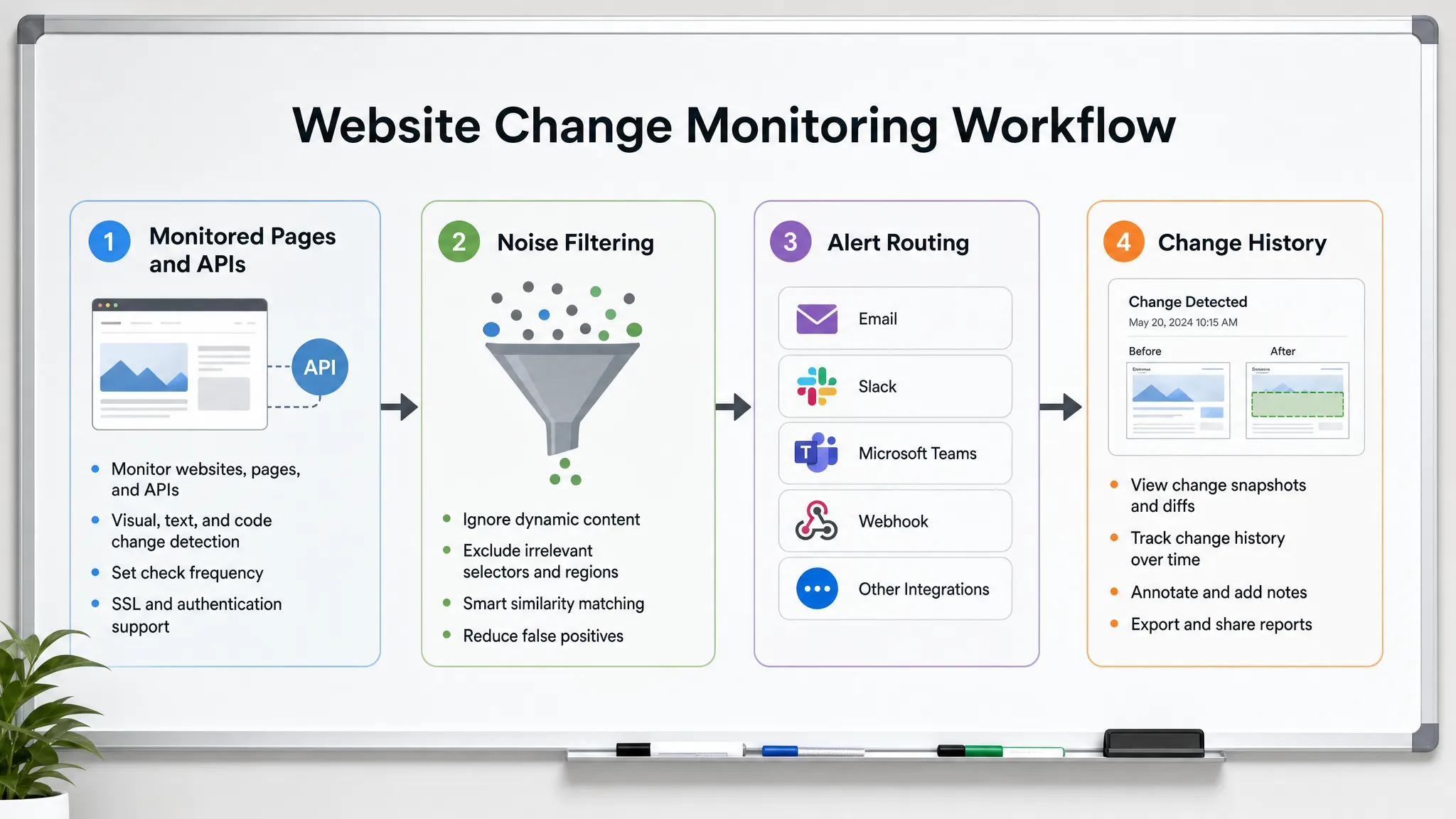
Rotear alertas para a pessoa que pode agir
Uma mudança detectada rapidamente, mas enviada para a caixa de entrada errada, ainda é uma resposta atrasada. O roteamento de alertas deve refletir a propriedade.
Alertas de preços devem ir para operações de receita, marketing de produto ou a pessoa que possui embalagens. Mudanças de linguagem legal devem ir para legal ou conformidade. Mudanças de API e alimentação devem ir para engenharia ou operações. Mudanças de concorrentes ou mercados podem pertencer a vendas, estratégia ou parcerias.
Os melhores alertas incluem contexto suficiente para reduzir a ida e vinda:
- A URL monitorada, alimentação ou ponto de extremidade de API.
- A mudança exata antes e depois.
- O tempo em que a mudança foi detectada.
- A gravidade ou categoria de negócios.
- O proprietário ou canal responsável pela revisão.
- O próximo passo, como validar, reverter, escalar ou atualizar sistemas internos.
Para equipes com pilhas operacionais mais complexas, os alertas podem precisar acionar fluxos de trabalho em CRMs, ERPs, sistemas de ticket ou automação interna. Se os sinais de mudanças no site precisam se conectar a processos de back-office mais amplos, trabalhar com especialistas em automação de IA e consultoria NetSuite pode ajudar a alinhar a detecção com os sistemas que as equipes já usam para executar o negócio.
Alertas do Slack e do e-mail são úteis para visibilidade. Webhooks e integrações de fluxo de trabalho são úteis quando uma mudança deve criar um ticket, atualizar um registro, notificar um sistema downstream ou iniciar um processo de revisão automaticamente.
Manter um histórico de cada mudança significativa
Alertas rápidos ajudam a responder no momento. O histórico de mudanças ajuda a entender o que aconteceu mais tarde.
Um histórico completo é valioso quando as equipes precisam responder a perguntas como:
- Quando este preço apareceu pela primeira vez?
- O que a política dizia antes da última atualização?
- A página do fornecedor mudou antes da reclamação do cliente?
- Qual campo de API mudou antes que o fluxo de trabalho falhasse?
- Foi um problema de uma vez ou parte de um padrão recorrente?
Sem histórico, as equipes dependem de capturas de tela, memória e threads de chat. Isso torna as revisões de incidentes mais lentas e menos confiáveis. Com um registro de auditoria, as equipes podem reconstruir eventos, comparar mudanças ao longo do tempo e melhorar as regras de monitoramento após cada incidente.
O histórico é especialmente importante para equipes sensíveis à conformidade. O objetivo não é apenas saber que uma página mudou, mas preservar evidências do que mudou e quando foi detectado.
Testar o fluxo de trabalho antes de um incidente real
Não espere uma reclamação de um cliente para descobrir se o monitoramento funciona. Execute testes controlados.
Para páginas internas que você controla, faça uma pequena mudança de teste em uma área de baixo risco e confirme que o alerta certo dispara. Para páginas externas, use páginas de baixo risco conhecidas para validar que o monitoramento detecta o tipo de conteúdo que você se importa. Para APIs, teste mudanças esperadas em um ambiente de staging ou seguro, quando possível.
Em seguida, revise o caminho completo. A mudança foi detectada rapidamente o suficiente? O alerta foi enviado para a pessoa certa? A resposta foi rápida o suficiente?