Un sitio web rara vez falla en un momento dramático. Con más frecuencia, una línea de precios cambia sin previo aviso, un mensaje de checkout desaparece, una política de proveedor cambia, un competidor actualiza un plan o una fuente devuelve un nuevo valor que rompe silenciosamente una suposición dentro de su negocio.
Si la primera persona en notar es un cliente, prospecto, socio o regulador, el costo ya es más alto. Los tickets de soporte comienzan. Los equipos de ventas explican precios desactualizados. Los equipos de cumplimiento investigan después del hecho. Los equipos de operaciones se apresuran a entender qué cambió y cuándo.
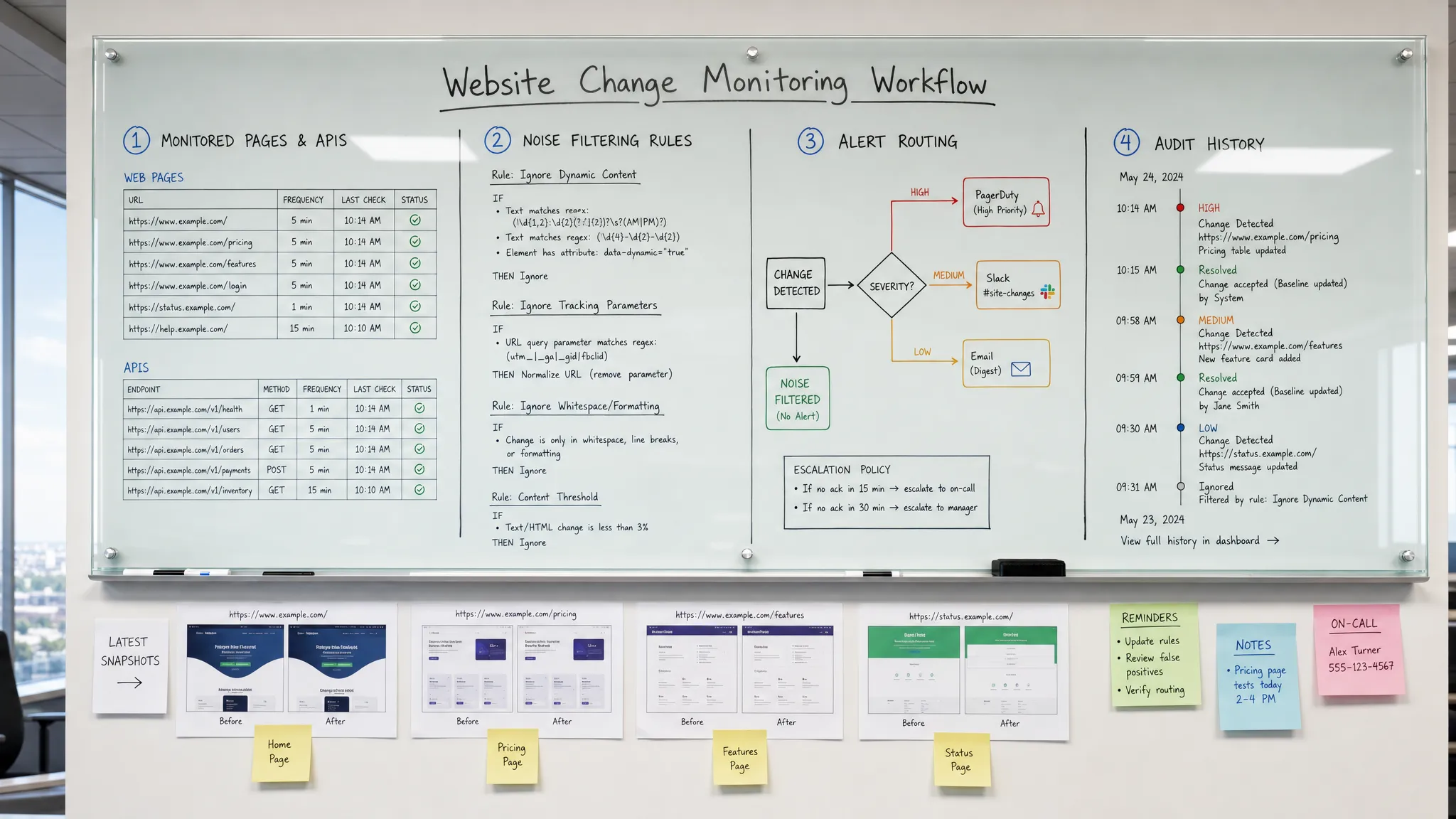
Para detectar los cambios en el sitio web antes de que los clientes lo hagan, necesita más que una herramienta que diga "esta página cambió". Necesita un flujo de trabajo de monitoreo que sepa qué cambios son importantes, verifique las fuentes correctas a la velocidad correcta, filtre el ruido y envíe alertas accionables a las personas que pueden responder.
Qué significa "antes de que los clientes lo hagan" en realidad
Detectar cambios temprano no se trata solo de velocidad. La velocidad es importante, especialmente para precios, políticas, checkout, disponibilidad y datos de socios, pero es solo una parte del sistema.
Un flujo de trabajo de alerta temprana práctico debe cerrar dos brechas:
- La brecha de detección, que es el tiempo entre un cambio que ocurre y su equipo que se entera de ello.
- La brecha de respuesta, que es el tiempo entre su equipo que se entera y el propietario correcto que toma acción.
Muchos equipos se enfocan solo en la primera brecha. Configuran un monitor, reciben demasiadas alertas y eventualmente dejan de confiar en ellas. El enfoque mejor es tratar la detección de cambios en el sitio web como un control operativo. Cada alerta debe responder: ¿qué cambió, por qué es importante, quién es el propietario y qué sucede a continuación?
Eso comienza con la elección de las superficies correctas para monitorear.
Mapa de las superficies web que los clientes dependen
No todas las páginas merecen la misma atención. Un error tipográfico en una publicación de blog antigua rara vez tiene la misma urgencia que una discrepancia de precios en una página de planes o un cambio en los términos de reembolso. La mejor manera de empezar es inventariar las superficies que influyen en los ingresos, el cumplimiento, la experiencia del cliente o las operaciones.
| Superficie para monitorear | Ejemplos | Por qué es importante | Propietario típico |
|---|
| Páginas de precios y embalaje | Nombres de planes, precios de lista, descuentos, límites de uso | Los clientes comparan, compran y cuestionan facturas en función de esta copia | Operaciones de ingresos, marketing de productos |
| Rutas de checkout y registro | Texto de CTA, campos de formulario, notificaciones de pago, disponibilidad | Pequeños cambios pueden reducir la conversión o crear problemas de soporte | Crecimiento, operaciones web |
| Páginas legales y de políticas | Términos, política de privacidad, política de reembolso, lenguaje de SLA | Los cambios pueden crear riesgos de cumplimiento o contractuales | Legal, cumplimiento |
| Documentos de productos y contenido de ayuda | Pasos de configuración, disponibilidad de funciones, notas de migración | Las instrucciones obsoletas aumentan los tickets y la frustración del cliente | Soporte, producto |
| Páginas de proveedores y socios | Términos de proveedor, listados de mercado, documentos de socios | Los cambios externos pueden afectar la entrega, los márgenes o las obligaciones | Operaciones, socios |
| Fuentes y API | Inventario, tarifas, fuentes de socios, valores de estado | Los cambios estructurados pueden romper flujos de trabajo posteriores | Ingeniería, operaciones |
Este paso de mapeo es donde muchos programas de monitoreo tienen éxito o fracasan. Si todo es "crítico", los equipos se ahogan en alertas. Si solo se monitorea la copia de la página de inicio, se pasan por alto los cambios de mayor riesgo.
Para un marco de trabajo más profundo sobre la priorización de superficies comerciales críticas, la guía de DiffHook sobre cómo monitorear una página web para cambios críticos es un compañero útil para este flujo de trabajo.
Defina qué cuenta como un cambio importante
Un diff sin procesar no es lo mismo que una señal útil. Las páginas modernas cambian constantemente. Las fechas de tiempo se actualizan, los anuncios rotan, los widgets de inventario se actualizan, los módulos de personalización intercambian contenido y los bloques de recomendación se mueven alrededor.
Antes de configurar el monitoreo, defina qué debe activar la acción. Por ejemplo, un equipo de precios puede preocuparse por un monto en dólares, un descuento porcentual o una frase como "solo plan anual". Un equipo de cumplimiento puede preocuparse por una fecha de vigencia de la política, un lenguaje de consentimiento o un lenguaje específico de la jurisdicción. Un equipo de operaciones puede preocuparse por la ventana de entrega de un proveedor, el tamaño mínimo de pedido o el valor de un campo de API.
Los buenos criterios de cambio son lo suficientemente específicos como para reducir el ruido, pero lo suficientemente amplios como para capturar el riesgo inesperado. En lugar de "alertarme cuando la página de precios cambie", una regla mejor es "alertar al equipo de ingresos cuando cambien los nombres de planes, precios, períodos de facturación, términos de descuento o límites incluidos".
Para API y fuentes, defina los cambios en términos de estructura y valores. Un nuevo campo puede ser inofensivo. Un campo que falta, un código de estado cambiado, un atributo renombrado o un rango de valores desplazado puede romper un flujo de trabajo. El mismo principio se aplica a las páginas: un nuevo testimonio suele ser de baja prioridad, mientras que una cláusula de cancelación eliminada puede ser urgente.
Elija el método de detección correcto para cada fuente
La frase "detectar cambios en el sitio web" cubre varios patrones técnicos diferentes. Una página HTML pública, una tabla de precios renderizada por JavaScript, un PDF de política, una fuente RSS y un punto final de API requieren un manejo diferente.
| Tipo de fuente | Enfoque de monitoreo práctico | Qué buscar |
|---|
| Páginas estáticas | Rastrear texto, HTML o secciones específicas de la página | Cambios de copia, secciones eliminadas, enlaces cambiados |
| Páginas dinámicas | Monitorear contenido renderizado o elementos de página estables | Precios cargados por JavaScript, formularios, CTAs |
| Bloques de precios | Rastrear valores exactos y términos clave | Cambios de precios, períodos de facturación, condiciones de descuento |
| Páginas de políticas | Rastrear texto a nivel de sección y fechas de vigencia | Actualizaciones de términos, cambios de privacidad, lenguaje de reembolso |
| Fuentes y API | Comparar respuestas, campos, códigos de estado y valores de carga | Cambios de esquema, datos que faltan, valores inesperados |
Las comprobaciones manuales no pueden manejar esto de manera confiable. Son lentas, inconsistentes y fáciles de omitir cuando los equipos están ocupados. Los marcadores de navegador y las hojas de cálculo pueden funcionar para un puñado de páginas, pero no proporcionan alertas rápidas, historial o enrutamiento.
El monitoreo automatizado debe coincidir con la fuente. Para una página de política, la comparación de texto puede ser suficiente. Para una página de precios, es posible que deba aislar la tabla de planes y ignorar los cambios de diseño no relacionados. Para una API, necesita monitorear la respuesta en sí, no solo si el punto final está activo.
Si su caso de uso depende de la velocidad, esta guía para comprobar una página para cambios en tiempo real explica por qué la detección en tiempo real requiere más que simplemente actualizar una URL.
Coincidir la frecuencia de monitoreo con el riesgo comercial
Algunas páginas deben monitorearse en tiempo real. Otros no necesitan comprobaciones constantes. La clave es alinear la velocidad de monitoreo con el costo de llegar tarde.
Los precios, el checkout, las políticas críticas, las páginas de proveedores de alto valor y las API que alimentan sistemas que enfrentan al cliente suelen merecer las alertas más rápidas. Un aviso retrasado puede llevar a ingresos perdidos, cotizaciones incorrectas, flujos de trabajo rotos o escalaciones de clientes evitables.
Las páginas de menor riesgo, como la copia de marketing general o la documentación evergreen, pueden no necesitar la misma urgencia. Aun así, se benefician del historial de cambios, pero pueden no requerir una escalada inmediata.
Un modelo de gravedad simple puede ayudar:
| Gravedad | Ejemplo de cambio | Momento de alerta | Expectativa de respuesta |
|---|
| Crítico | Discrepancia de precios pública, ruptura de checkout, cláusula de política eliminada | Inmediato | El propietario investiga ahora |
| Alto | Cambio de precios de competidor, actualización de términos de proveedor, cambio de campo de API | Rápido | El propietario revisa el mismo día |
| Medio | Actualización de artículo de ayuda, cambio de copia de página no crítico | Programado | Revisar durante el flujo de trabajo normal |
| Bajo | Ajuste de diseño, reemplazo de imagen, cambio menor de metadatos | Resumen o historial solo | No se requiere acción inmediata |
Esto evita la trampa común de tratar cada cambio como una emergencia. El objetivo no es crear más alertas. El objetivo es crear señales más tempranas y confiables.
Filtrar el ruido antes de que llegue a las personas
El ruido es el enemigo de la detección temprana. Si un monitor alerta sobre cada variación del banner de cookies, la imagen del héroe que gira, la fecha de tiempo, o un bloque personalizado, las personas lo silenciarán. Una vez que las alertas se ignoran, el sistema de monitoreo deja de proteger el negocio.
Los filtros útiles dependen de la página y el equipo. Puede que desee ignorar la navegación, los pies de página, los anuncios, el contenido relacionado, los ID de sesión, los parámetros de seguimiento o los bloques que cambian en cada carga. Para los precios, puede que desee alertas solo cuando cambian los valores numéricos o los términos de plan. Para las páginas de políticas, puede que desee diferencias a nivel de sección en lugar de ruido de página completa.
El filtrado inteligente no debe ocultar el riesgo. Debe eliminar los cambios predecibles y de bajo valor para que los cambios significativos se destaquen. La prueba correcta es simple: ¿la alerta ayudaría a alguien a tomar una decisión? Si no, refine el monitor.
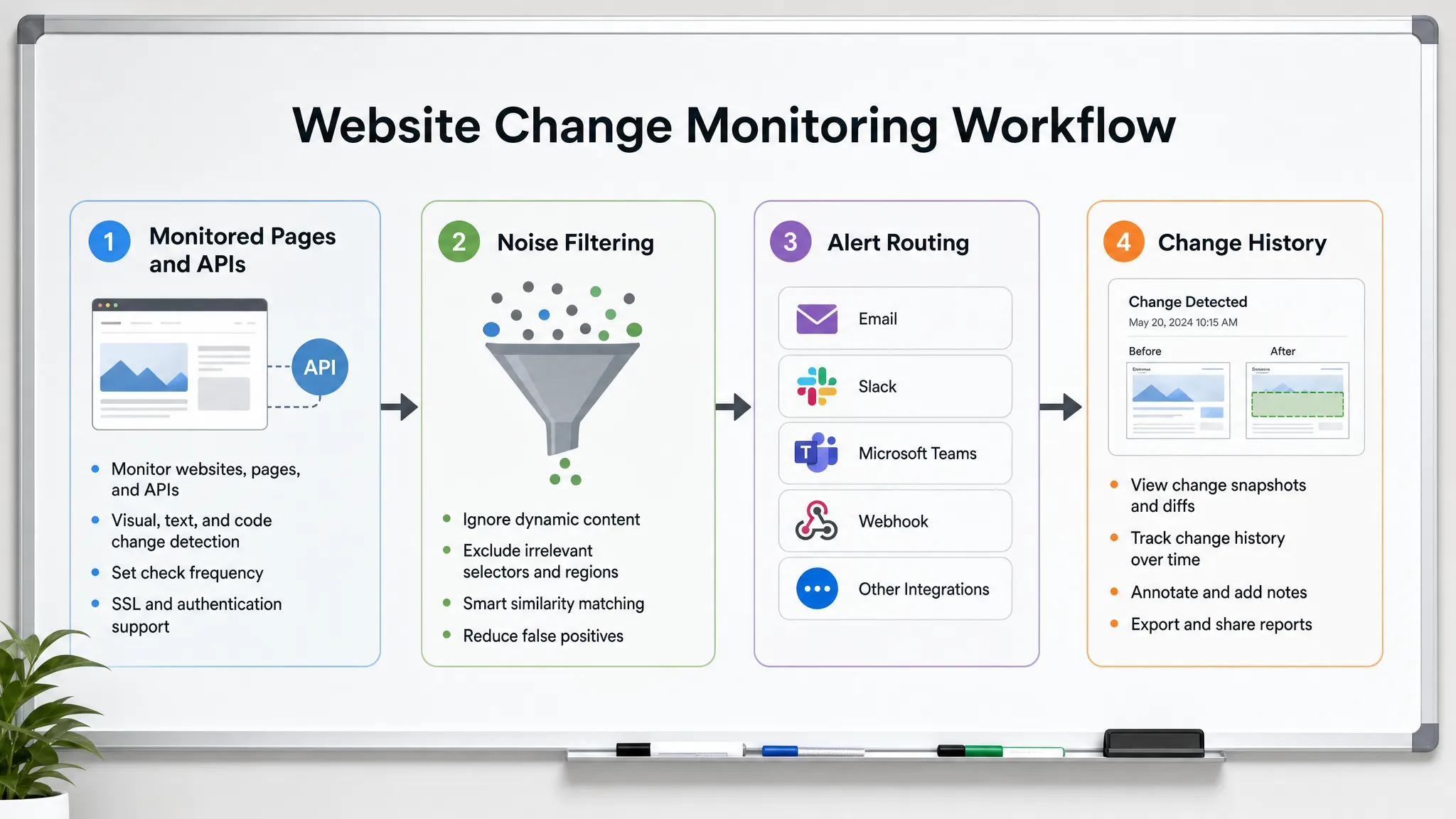
Enrutar alertas a la persona que puede actuar
Un cambio detectado rápidamente pero enviado a la casilla de correo incorrecta todavía es una respuesta retrasada. La ruta de alerta debe reflejar la propiedad.
Las alertas de precios deben ir a las operaciones de ingresos, el marketing de productos o la persona que posee el embalaje. Los cambios en el lenguaje legal deben ir a legal o cumplimiento. Los cambios de API y fuente deben ir a ingeniería o operaciones. Los cambios de competidores o de mercado pueden pertenecer a ventas, estrategia o socios.
Las mejores alertas incluyen suficiente contexto para reducir el vaivén:
- La URL monitoreada, la fuente o el punto final de API.
- El cambio exacto antes y después.
- La hora en que se detectó el cambio.
- La gravedad o categoría comercial.
- El propietario o canal responsable de la revisión.
- El siguiente paso, como validar, revertir, escalar o actualizar sistemas internos.
Para los equipos con pilas operativas más complejas, las alertas pueden necesitar activar flujos de trabajo en CRM, ERP, sistemas de ticketing o automatización interna. Si las señales de cambios en el sitio web necesitan conectarse a procesos de back-office más amplios, trabajar con especialistas en automatización de IA y consultoría de NetSuite puede ayudar a alinear la detección con los sistemas que los equipos ya usan para ejecutar el negocio.
Las alertas de Slack y correo electrónico son útiles para la visibilidad. Los webhooks y las integraciones de flujo de trabajo son útiles cuando un cambio debe crear un ticket, actualizar un registro, notificar un sistema posterior o iniciar un proceso de revisión automáticamente.
Mantener un historial de cada cambio significativo
Las alertas rápidas ayudan a responder en el momento. El historial de cambios ayuda a entender qué sucedió más tarde.
Un historial completo es valioso cuando los equipos necesitan responder a preguntas como:
- ¿Cuándo apareció este precio por primera vez?
- ¿Qué decía la política antes de la última actualización?
- ¿Cambió la página del proveedor antes de la queja del cliente?
- ¿Qué campo de API cambió antes de que fallara el flujo de trabajo?
- ¿Fue esto un problema de un solo tiempo o parte de un patrón recurrente?
Sin historial, los equipos dependen de capturas de pantalla, memoria y hilos de chat. Eso hace que las revisiones de incidentes sean más lentas y menos confiables. Con una pista de auditoría, los equipos pueden reconstruir eventos, comparar cambios con el tiempo y mejorar las reglas de monitoreo después de cada incidente.
El historial es especialmente importante para los equipos sensibles al cumplimiento. El objetivo no es solo saber que una página cambió, sino preservar la evidencia de qué cambió y cuándo se detectó.
Probar el flujo de trabajo antes de un incidente real
No espere a una queja de un cliente para descubrir si su monitoreo funciona. Realice pruebas controladas.
Para páginas internas que controla, realice un pequeño cambio de prueba en un área de bajo riesgo y confirme que se dispara la alerta correcta. Para páginas externas, use páginas de bajo riesgo conocidas para validar que su monitoreo detecta el tipo de contenido que le importa. Para API, pruebe los cambios esperados en un entorno de ensayo o seguro cuando sea posible.
Luego revise el camino completo. ¿Se detectó el cambio con suficiente rapidez? ¿Se envió la alerta a la persona correcta? ¿Se tomó la acción correcta?